Postgres
Теги: data-bases bd
* Статья является сокращением “Postgresql знакомство” Лузанов, Лёвшин, Рогов и “Оптимизация запросов в Postgresql” Домбровская, Новиков, Бейликова.
PostgreSQL обеспечивает полную поддержку свойств ACID и обеспечивает эффективную изоляцию транзакций. Для этого в PostgreSQL используется механизм многоверсионного управления одновременным доступом (MVCC), который позволяет обходиться без блокировок строк во всех случаях, кроме одновременного изменения одной и той же строки данных в нескольких процессах: читающие транзакции никогда не блокируют пишущих транзакций, а пишущие — читающих.
Это справедливо и для самого строгого уровня изоляции serializable, который, используя инновационную систему Serializable Snapshot Isolation, обеспечивает полное отсутствие аномалий сериализации и гарантирует, что при одновременном выполнении транзакций результат будет таким же, как и при последовательном выполнении.
PostgreSQL эффективно использует современную архитектуру многоядерных процессоров — производительность СУБД растет практически линейно с увеличением количества ядер.
Есть возможность параллельного выполнения запросов: PostgreSQL умеет распараллеливать чтение данных и соединения (в том числе и для секционированных таблиц), выполнять в параллельном режиме ряд служебных команд (создание индексов, очистку). JIT-компиляция запросов повышает возможности использования аппаратных средств для ускорения операций.
В PostgreSQL реализованы различные способы индексирования. Помимо традиционных B-деревьев доступно множество других методов доступа:
- Hash — индекс на основе хеширования. В отличие от B-деревьев, такие индексы работают только при проверке на равенство, но в ряде случаев могут оказаться компактнее и эффективнее.
- GiST — обобщенное сбалансированное дерево поиска, которое применяется для данных, не допускающих упорядочения. Примерами могут служить R-деревья для индексирования точек на плоскости с возможностью быстрого поиска ближайших соседей (kNN search) и индексирование операции пересечения интервалов.
- SP-GiST — обобщенное несбалансированное дерево, основанное на разбиении области значений на непересекающиеся вложенные области. Примерами могут служить дерево квадрантов для пространственных данных и префиксное дерево для текстовых строк.
- GIN — обобщенный инвертированный индекс, который используется для сложных значений, состоящих из элементов. Основной областью применения является полнотекстовый поиск, где требуется находить документы, в которых встречается указанные в поисковом запросе слова. Другим примером использования является поиск значений в массивах данных
- RUM — дальнейшее развитие метода GIN для полнотекстового поиска. Этот индекс, доступный в виде расширения, позволяет ускорить фразовый поиск и сразу выдавать результаты упорядоченными по релевантности.
- BRIN — компактная структура, позволяющая найти компромисс между размером индекса и скоростью поиска. Такой индекс эффективен на больших кластеризованных таблицах.
- Bloom — индекс, основанный на фильтре Блума. Такой индекс, имея очень компактное представление, позволяет быстро отсечь заведомо ненужные строки, однако требует перепроверки оставшихся
Многие типы индексов могут создаваться не только по одному, но и по нескольким столбцам таблицы. Независимо от типа можно строить индексы как по столбцам, так и по произвольным выражениям, а также создавать частичные индексы только для определенных строк. Покрывающие индексы позволяют ускорить запросы за счет того, что все необходимые данные извлекаются из самого индекса без обращения к таблице. В арсенале планировщика имеется сканирование по битовой карте, которое позволяет объединять сразу несколько индексов для ускорения доступа
Пользователи могут самостоятельно, не меняя базовый код системы, добавлять:
- типы данных,
- функции и операторы для работы с новыми типами,
- индексные и табличные методы доступа,
- языки серверного программирования,
- подключения к внешним источникам данных (Foreign Data Wrappers),
- загружаемые расширения
Подключение с помощью psql
sudo -u postgres psql
Создание БД
postgres=# CREATE DATABASE test;
CREATE DATABASE
postgres=# \c test
You are now connected to database "test" as user "postgres".
test=#
Команды, начинающиеся с \ - это специальные команды psql. Они не доступны в обычных SQL-запросах.
Создание таблицы
test=# CREATE TABLE courses( test(#
c_no text PRIMARY KEY,
test(# title text,
test(# hours integer
test(# );
CREATE TABLE
В этой командемыопределили, что таблица с именем courses будет состоять из трех столбцов: c_no — текстовый номер курса, title — название курса, и hours — целое число лекционных часов. Кроме столбцов и типов данных мы можем определить ограничения целостности, которые будут автоматически проверяться — СУБД не допустит появление в базе некорректных данных. В нашем примере мы добавили ограничение PRIMARY KEY для столбца c_no, которое говорит о том, что значения в этом столбце должны быть уникальными, а неопределенные значения не допускаются. Такой столбец можно использовать для того, чтобы отличить одну строку в таблице от других. Полный список ограничений целостности
Добавляем даныне
test=# INSERT INTO courses(c_no, title, hours)
VALUES ('CS301', 'Базы данных', 30),
('CS305', 'Сети ЭВМ', 60);
INSERT 0 2
Смотри загрузку данных из ф-ла
Для дальнейших примеров нам потребуется еще две таблицы: студенты и экзамены. Для каждого студента будем хранить его имя и год поступления; идентифицироваться он будет числовым номером студенческого билета.
test=# CREATE TABLE students(
s_id integer PRIMARY KEY,
name text,
start_year integer
);
CREATE TABLE
test=# INSERT INTO students(s_id, name, start_year)
VALUES (1451, 'Анна', 2014),
(1432, 'Виктор', 2014),
(1556, 'Нина', 2015);
INSERT 0 3
Экзамен содержит оценку, полученную студентом по некоторой дисциплине. Таким образом, студенты и дисциплины связаны друг с другом отношением «многие ко многим»: один студент может сдавать экзамены по многим дисциплинам, а экзамен по одной дисциплине могут сдавать много студентов.
Запись в таблице экзаменов идентифицируется совокупностью номера студбилета и номера курса. Такое ограничение целостности, относящее сразу к нескольким столбцам, определяется с помощью фразы CONSTRAINT
test=# CREATE TABLE exams(
s_id integer REFERENCES students(s_id),
c_no text REFERENCES courses(c_no),
score integer,
CONSTRAINT pk PRIMARY KEY(s_id, c_no)
);
CREATE TABLE
Кроме того, с помощью фразы REFERENCES мы определили два ограничения ссылочной целостности, называемые внешними ключами. Такие ограничения показывают, что значения в одной таблице ссылаются на строки в другой таблице.
Теперь при любых действиях СУБД будет проверять, что все идентификаторы s_id, указанные в таблице экзаменов, соответствуют реальным студентам (то есть записям в таблице студентов), а номера c_no — реальным курсам. Таким образом, будет исключена возможность оценить несуще- ствующего студента или поставить оценку по несуществующей дисциплине
SQL-запросы
Простые
Две колонки
test=# SELECT title AS course_title, hours FROM courses;
course_title | hours
--------------+-------
Базы данных | 30
Сети ЭВМ | 60
(2 rows)
Все что есть в таблице
test=# SELECT * FROM courses;
c_no | title | hours
-------+-------------+-------
CS301 | Базы данных | 30
CS305 | Сети ЭВМ | 60
(2 rows)
Убираем дублирующие значения с помощью DISTINCT
test=# SELECT DISTINCT start_year FROM students;
start_year
------------
2014
2015
(2 rows)
С условием для SELECT
test=# SELECT * FROM courses WHERE hours > 45;
c_no | title | hours
-------+----------+-------
CS305 | Сети ЭВМ | 60
(1 row)
Условие должно иметь логический тип. Например, оно может содержать отношения =, <> (или !=), >, >=, <, <=; может объединять более простые условия с помощью логических операций AND, OR, NOT и круглых скобок — как в обычных языках программирования.
В результирующую таблицу попадают только те строки, для которых условие фильтрации истинно; если же значение ложно или не определено, строка отбрасывается:
- результат сравнения чего-либо с неопределенным значением не определен;
- результат логических операций с неопределенным значением, как правило, не определен (исключения: true OR NULL = true, false AND NULL = false);
- для проверки определенности значения используются специальные отношения IS NULL (IS NOT NULL) и IS DISTINCT FROM (IS NOT DISTINCT FROM), а также бывает удобно воспользоваться функцией coalesce
Соединения
Грамотно спроектированная реляционная база данных не содержит избыточных данных. Например, таблица экзаменов не должна содержать имя студента, потому что его можно найти в другой таблице по номеру студенческого билета.
Поэтому для получения всех необходимых значений в запросе часто приходится соединять данные из нескольких таблиц, перечисляя их имена во фразе FROM
test=# SELECT * FROM courses, exams;
То, что получилось, называется прямым или декартовым произведением таблиц — к каждой строке одной таблицы добавляется каждая строка другой.
Как правило, более полезный и содержательный результат можно получить, указав во фразе WHERE условие соединения
test=# SELECT courses.title, exams.s_id, exams.score
FROM courses, exams
WHERE courses.c_no = exams.c_no;
title | s_id | score
-------------+------+-------
Базы данных | 1451 | 5
Базы данных | 1556 | 5
Сети ЭВМ | 1451 | 5
Сети ЭВМ | 1432 | 4
(4 rows)
Запросы можно формулировать и в другом виде, указывая соединения с помощью ключевого слова JOIN
test=# SELECT students.name, exams.score
FROM students
JOIN exams
ON students.s_id = exams.s_id
AND exams.c_no = 'CS305';
name | score
--------+-------
Анна | 5
Виктор | 4
(2 rows)
С точки зрения СУБД обе формы эквивалентны, так что можно использовать тот способ, который представляется более наглядным.
Этот пример показывает, что в результат не включаются строки исходной таблицы, для которых не нашлось пары в другой таблице: хотя условие наложено на дисциплины, но при этом исключаются и студенты, которые не сдавали экзамен по данной дисциплине. Чтобы в выборку попали все студенты, надо использовать внешнее соединение:
test=# SELECT students.name, exams.score
FROM students
LEFT JOIN exams
ON students.s_id = exams.s_id
AND exams.c_no = 'CS305';
name | score
--------+-------
Анна | 5
Виктор | 4
Нина |
(3 rows)
В этом примере в результат добавляются строки из левой таблицы (поэтому операция называется LEFT JOIN), для которых не нашлось пары в правой. При этом для столб- цов правой таблицы возвращаются неопределенные значения
Условия во фразе WHERE применяются к уже готовому результату соединений, поэтому, если вынести ограничение на дисциплины из условия соединения, Нина не попадет в выборку — ведь для нее exams.c_no не определен:
test=# SELECT students.name, exams.score
FROM students
LEFT JOIN exams
ON students.s_id = exams.s_id
WHERE exams.c_no = 'CS305';
name | score
--------+-------
Анна | 5
Виктор | 4
(2 rows)
Соединения - это обычная и естественная для реляционных СУБД операция, и у PostgreSQL имеется целый арсенал эффективных механизмов для ее выполнения. Не соединяйте данные в приложении, доверьте эту работу серверу баз данных. Подробнее
Позапросы
Оператор SELECT формирует таблицу, которая может быть выведена в качестве результата, а может быть использована в другой конструкции языка SQL в любом месте, где по смыслу может находиться таблица. Такая вложенная команда SELECT, заключенная в круглые скобки, называется подзапросом
Если подзапрос возвращает ровно одну строку и ровно один столбец, его можно использовать как обычное скалярное выражение
test=# SELECT name,
(SELECT score
FROM exams
WHERE exams.s_id = students.s_id
AND exams.c_no = 'CS305')
FROM students;
name | score
--------+-------
Анна | 5
Виктор | 4
Нина |
(3 rows)
Скалярные подзапросы можно также использовать в условиях фильтрации
test=# SELECT * FROM exams
WHERE (SELECT start_year
FROM students
WHERE students.s_id = exams.s_id) > 2014;
s_id | c_no | score
------+-------+-------
1556 | CS301 |
5 (1 row)
В SQL можно формулировать условия и на подзапросы, возвращающие произвольное количество строк. Для этого существует несколько конструкций, одна из которых — отношение IN — проверяет, содержится ли значение в таблице, возвращаемой подзапросом. В примере ниже выводятся даныне студентов, у которых есть какие-либо оценки.
test=# SELECT name, start_year
FROM students
WHERE s_id IN (SELECT s_id FROM exams WHERE c_no = 'CS305');
name | start_year
--------+------------
Анна | 2014
Виктор | 2014
(2 rows)
Отношение NOT IN возвращает противоположный результат. Еще одна возможность — использовать предикат EXISTS, проверяющий, что подзапрос возвратил хотя бы одну строку.
test=# SELECT name, start_year
FROM students
WHERE NOT EXISTS (SELECT s_id FROM exams WHERE exams.s_id = students.s_id AND score = 5);
name | start_year
--------+------------
Виктор | 2014
(1 row)
после подзапроса можно указать произвольное имя, которое называется псевдонимом (alias). Псевдонимы можно использовать и для обычных таблиц. Здесь s — псевдоним таблицы, а ce — псевдоним подзапроса.
test=# SELECT s.name, ce.score
FROM students s
JOIN (SELECT exams.*
FROM courses, exams
WHERE courses.c_no = exams.c_no
AND courses.title = 'Базы данных') ce
ON s.s_id = ce.s_id;
Сортировка
Данные в таблицах не упорядочены, но часто бывает важно получить строки результата в строго определенном порядке. Для этого используется предло- жение ORDER BY со списком выражений, по которым надо выполнить сортировку. После каждого выражения (ключа сортировки) можно указать направление: ASC — по воз- растанию (этот порядок используется по умолчанию) или DESC — по убыванию. Операцию сортировки имеет смысл выполнять в конце запроса непосредственно перед получением результата; в подзапросах она обычно бессмысленна.
test=# SELECT * FROM exams ORDER BY score, s_id, c_no DESC;
s_id | c_no | score
------+-------+-------
1432 | CS305 | 4
1451 | CS305 | 5
1451 | CS301 | 5
1556 | CS301 | 5
(4 rows)
Здесь
Группировка
При группировке в одной строке результата размещается значение, вычисленное на основании данных нескольких строк исходных таблиц. Вместе с группировкой используют агрегатные функции. Например, общее количество проведенных экзаменов, количество сдававших их студентов и средний балл:
test=# SELECT count(*), count(DISTINCT s_id), avg(score)
FROM exams;
count | count | avg
-------+-------+--------------------
4 | 3 | 4.7500000000000000
(1 row)
В разбивке по номерам курсов с помощью предложения GROUP BY, в котором указываются ключи группировки:
test=# SELECT c_no, count(*), count(DISTINCT s_id), avg(score)
FROM exams
GROUP BY c_no;
c_no | count | count | avg
-------+-------+-------+--------------------
CS301 | 2 | 2 | 5.0000000000000000
CS305 | 2 | 2 | 4.5000000000000000
(2 rows)
Подробнее об агрегатных функциях
В запросах, использующих группировку, может возникнуть необходимость отфильтровать строки на основании результатов агрегирования. Такие условия можно задать в предложении HAVING. Отличие от WHERE состоит в том, что условия WHERE применяются до группировки (в них можно использовать столбцы исходных таблиц), а условия HAVING — после группировки (и в них можно также использовать столбцы таблицы-результата). Подробнее
Изменение/удаление данных
Изменение данных в таблице выполняет оператор UPDATE, в котором указываются новые значения полей для строк, определяемых предложением WHERE (таким же, как в операторе SELECT). Оператор DELETE удаляет из указанной таблицы строки, определяемые все тем же предложением WHERE
test=# UPDATE courses
SET hours = hours * 2
WHERE c_no = 'CS301';
UPDATE 1
test=# DELETE FROM exams
WHERE score < 5;
DELETE 1
Транзакции
Когда две операции надо совершить одновременно, потому что ни одна из них не имеет смысла без другой или данные одной приведут к несогласованному состоянию без данных второй. Такие операции, составляющие логически неделимую единицу работы, называются транзакцией.
test=# BEGIN;
BEGIN
test=*# INSERT INTO groups(g_no, monitor)
SELECT 'A-101', s_id
FROM students WHERE name = 'Анна';
INSERT 0 1
test=*# COMMIT;
COMMIT
Звездочка в данном случае напоминает об открытой и незавершенной транзакции.
СУБД дает несколько очень важных гарантий:
- Во-первых, любая транзакция либо выполняется целиком, либо не выполняется совсем. Если бы в одной из команд произошла ошибка, или мы самипрервали бы транзакцию командой ROLLBACK, то база данных осталась бы в том состоянии, в котором она была до команды BEGIN. Это свойство называется атомарностью.
- Во-вторых, когда фиксируются изменения транзакции, все ограничения целостности должны быть выполнены, иначе транзакция прерывается. В начале работы транзакции данные находятся в согласованном состоянии, и в конце своей работы транзакция оставляет их согласованными; это свойство так и называется — согласованность.
- В-третьих, другие пользователи никогда не увидят несогласованные данные, которые транзакция еще не зафиксировала. Это свойство называется изоляцией; за счет его соблюдения СУБД способна параллельно обслуживать много сеансов, не жертвуя корректностью данных. Особенностью PostgreSQL является очень эффективная реализация изоляции: несколько сеансов могут одновременно читать и изменять данные, не блокируя друг друга. Блокировка возникает только при одновременном изменении одной и той же строки двумя разными процессами.
- И в-четвертых, гарантируется долговечность: зафиксированные данные не пропадут даже в случае сбоя.
Полезные команды psql
\?Справка по командам psql.\hСправка по SQL: список доступных команд или синтаксис конкретной команды.\xереключает традиционный табличный вывод (столбцы и строки) на расширенный (каждый столбец на отдельной строке) и обратно. Удобно для просмотра нескольких «широких» строк.\lСписок баз данных. Список пользователей.\duСписок пользователей.\dtСписок таблиц. Список индексов.\diСписок индексов.\dvСписок представлений.\dfСписок функций.\dnСписок схем.\dxСписок установленных расширений.\dpСписок привилегий.\d имяПодробная информация по конкретному объ- екту базы данных.\d+ имяИ еще более подробная информация по кон- кретному объекту.\timing onПоказывать время выполнения операторов\qВыход
Оптимизация запросов к postgres
В postgres три этапа компиляции запроса:
- компиляция sql-запроса в выражение, состоящее из логических выражений высокого уровня (логический план)
- оптимизация логического плана и превращение его в план исполнения (физический план выполнения)
- интерпретация плана и возврат результата
На первом этапе, при компиляции логического плана запросы от пользователя преобразуются в такой же декларативный запрос. Этот план определяет возможный порядок операций, но не способ их выполнения. План выполнения зависит от структуры бд. На втором этапе, при оптимизации, план выполнения преобразуется в инструкцию по выполнению - здесь логические операции заменяются на алгоритмы выполнения и изменяется порядок выполнения логических операций. Это делается основываясь на оценки стоимости выполнения алгоритмов. На третьем этапе план выполнения интепретируется движком и возвращается результат.
Оптимизация sql-запроса зависит от двух вещей: высокая вариативность запроса (широкий выбор возможностей замены на эквивалентым интерпретаторов postgres) и отсутствие побочных эффектов реляционных операций (таких как временные таблицы и т.п.). Т.е. операции должны быть как можно более декларативные (запрос не должен пытаться следовать императивной логике) и все что они должны порождать - это результат операции.
Алгоритмы доступа к данным
Селективность - соотношение количества строк в результате к количеству строк в сохраненной таблице. Выбор алгоритма роперации чтения и очередность операций фильтрации зависит от селективности.
Строки таблицы хранятся с использованием кучи (heap), что позволяет делать вставку без переупорядочивания.
Строки в бд хранятся блоками определенной длины в байтах. Несколько строк могут храниться в одном блоке. При полном сканировании движок бд считывает таблицу блоками и построчно из блоков для каждой строки проверяет условие фильтрации.
for each block in table loop
read block
for each row in block loop
if condition(row)
then output(row)
end if
end loop
end loop
fullcost = C1*BR + C2*TR + C3*S*TR, где BR - кол-во операций ввода-вывода, TR общее число итераций внутри внешнего цикла, S - селективность, а С1, С2, С3 - константы определяющие аппаратное обеспечение.
Для убыстрения доступа к данным в postgres создаются избыточные структуры - индексы. Они не хранят никакой дополнительной информации для таблицы и используются только для повышения производительности. Индексы определяют дополнительные пути доступа к строкам в блоках за счет хранения указателей на блоки, содержащие строки соответствующие условиям филтрации. Только эти блоки читаются при сканировании на оснвое индексов. Postgres использует две операции для получения данных по индексу:
- индексное скинрование (index scan) - сканируется весь индекс, в этом же порядке извлекаются блоки. Т.к. бд - это куча, несколько индексов могут указывать на один и тот же блок
- сканирование по битовой карте (bitmap heap scan) - битовая карта содержит карту блоков, содержащих необходимые строки, чтобы исключить повторное чтение.
Чем меньше селективность, тем выше вероятность, что все строки будут в разных блоках, а значит стоимость будет пропорциональна количеству возвращаемых строк. При большой селективности стоимость доступа может превысить полное сканирование, т.к. доступ к индексу сам по себе требует дополнительного цикла.
Кроме того, используется сканирование только индекса - это полезно, когда индекс содержит все необходимые для фильтрации поля. Стоимость такой модели аналогична индексному сканированию за исключением того, что не требуется извлечение блоков. Стоимост ьпросмотра индекса обычно в целом ниже, чем стоимость полного просмотра таблицы.
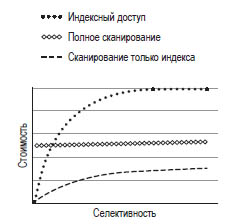
Основные индексные алгоритмы в postgres:
- B-деревья (позволяют делать дешевую вставку) - стандарт для всех бд
- битовые карты используются для компактного представления свойств табличных данных
- хеши позволяют эффективно выполнять операции точног осравнения
- R-дерево позволяет искать в пространственных данных с небольшим числом измерений (2-3)
План выполнения
Для построения плана оптимизатор использует правила преобразования, эвристики и алгоритмы оптимизации на основе стоимости выполнения. Алгоритм оптимизации выбирает план с самой низкой стоимостью выполнения. Т.к. пространство поиска такого плана огромно, оценка производится приблизительно за счет эвристик.
План выполнения представлен в виде дерева физических операций, где узлы - это операции, а стрелки - операнды. Большинство планов запросов удобно читать в текстовом, а не графическом виде.
Оценки плана неточны, т.к. неточны оценки стоимсоти выполнения операций по чтению данных. Кроме того, поиск оптимального плана затратен и для оптимизации этого поиска используются статистики данных конкретно БД, хранимые в виде гистограм. Кроме того, эвристические подходы к оценке оптимальности могут исключать оптимальный план на этапе примененеия эвристик. В этом случае требуется вмешательство инженера.
План выполнения можно получить с помощью sql-команды EXPLAIN
Смотри еще:
- docker image
- [2022-07-04-daily-note] Postgres Initialization scripts
- команды SQL, поддержвивемые в postgres pro
- PostgreSQL wildcard LIKE for any of a list of words
- pg_config executable not found проблема установки в linux
- PostgreSQL-триггеры: создание, удаление, примеры
- Inserting related data into two tables using in psql
- Killing/cancelling a long running Postgres query
- How to list indexes created for table in postgres
- [psycopq]
- [bd]
- [sql]
- [ormar]