Stable baseline 3
Install
Со всеми зависимостями: pip install stable-baselines3[extra] (tensorboard and etc)
Проблема установки (python 3.10+) - полечить: pip install -U setuptools==65.5.0
Для запуска визализаций возможно потребуется поставить более старую версию: pip install pyglet==1.5.27
Чтобы поставить в докере нужен nvidia-docker
Другие известные проблемы
- AttributeError: module ‘gym.envs.box2d’ has no attribute ‘LunarLander’
- AttributeError: module ‘_Box2D’ has no attribute ‘RAND_LIMIT_swigconstant’
Ограничения
Алгоритмы [reinforcement-learning] без моделей SB3 обычно неэффективны с точки зрения выборки. Им требуется множество примеров (иногда миллионы взаимодействий), чтобы узнать что-то полезное. Вот почему большая часть успехов в RL была достигнута только в играх или симуляциях. Общий совет: для повышения производительности следует увеличить бюджет агента (количество временных шагов обучения). Для достижения желаемого поведения часто требуются экспертные знания для разработки адекватной функции вознаграждения. Эта разработка вознаграждения требует нескольких итераций. В качестве хорошего примера формирования вознаграждения вы можете взглянуть на статью Deep Mimic, которая сочетает в себе имитационное обучение и обучение с подкреплением для выполнения акробатических движений. Последним ограничением RL является нестабильность обучения. То есть вы можете наблюдать во время тренировки огромное падение производительности. Такое поведение особенно характерно для DDPG, поэтому его расширение TD3 пытается решить эту проблему. Другой метод, такой как TRPO или PPO, использует trust region, чтобы свести к минимуму эту проблему, избегая слишком большого обновления.
Поскольку большинство алгоритмов во время обучения используют исследовательский шум, вам потребуется отдельная тестовая среда для оценки производительности вашего агента в заданное время. Рекомендуется периодически оценивать вашего агента для n тестовых эпизодов (n обычно составляет от 5 до 20) и усреднять вознаграждение за эпизод, чтобы получить точную оценку.
Поскольку некоторые политики являются стохастическими по умолчанию (например, A2C или PPO), вы также должны попытаться установить deterministic=True при вызове метода .predict(), это часто приводит к повышению производительности.
DQN поддерживает только дискретные действия, тогда как SAC ограничен непрерывными действиями.
Если важно время обучения (оно ограничено), то ледует выбрать A2C и его производные (PPO и т.д.). Стоит выбрать векторизованные среды, чтобы распараллелить обучение (если это позволяет алгоритм).
DQN с расширениями (двойной DQN, prioritized replay и т. д.) являются рекомендуемыми алгоритмами для дискретных действий с одним процессом. DQN обычно медленнее обучается, но является наиболее эффективным (из-за своего буфера воспроизведения).
Для распараллеленных дискретных сред PPO или A2C. Следует использовать гиперпараметры с rl-baselines3-zoo.
Для однопроцессных непрерывных сред сотой являеются SAC, TD3 и TQC.
Для многопроцессорных - PPO, TRPO или A2C. Опять же, не забудьте взять гиперпараметры из rl-baselines3-zoo для задач с непрерывными действиями.
Если ваша среда соответствует интерфейсу GoalEnv (см. HER), вам следует использовать HER + (SAC/TD3/DDPG/DQN/QR-DQN/TQC) в зависимости от области применения.
- Ввсегда нормализуйте свое пространство наблюдений, когда есть такая возможность (т.е. когда известны предельные значения)
- Нормализуйте свое пространство действий и сделайте его симметричным, когда оно непрерывное. Хорошей практикой является изменение масштаба ваших действий, чтобы они находились в [-1, 1]. Это не ограничивает вас, так как вы можете легко масштабировать действие внутри среды.
- Начните с сформированного вознаграждения (т. е. информативного вознаграждения) и упрощенной версии вашей проблемы. Не усложняйте задачу на старте.
- Отладьте случайными действиями, чтобы убедиться, что ваша среда работает и соответствует интерфейсу gym
- При создании пользовательской среды следует помнить о двух важных вещах: не нарушать марковский принцип и правильно обрабатывать завершение из-за тайм-аута (максимальное количество шагов в эпизоде). Например, если есть некоторая задержка между действием и наблюдением (например, из-за связи по Wi-Fi), вы должны предоставить историю наблюдений в качестве входных данных.
- Прекращение из-за тайм-аута (максимальное количество шагов в эпизоде) необходимо обрабатывать отдельно.
Мы рекомендуем выполнить следующие шаги, чтобы иметь работающий алгоритм RL на основе статьи исследования:
- Прочтите исходную статью несколько раз
- Изучите существующие реализации (если доступны)
- Старайтесь протестироватьалгоритм на игрушечных задачах.
- Подтвердите реализацию, заставив ее работать на все более и более сложных средах. Обычно для этого шага необходимо запустить оптимизацию гиперпараметров.
- Вы должны быть особенно осторожны с размерностью различных объектов, которыми вы манипулируете
- Не забудьте отдельно обрабатывать прерывание из-за тайм-аута
Алгоритмы
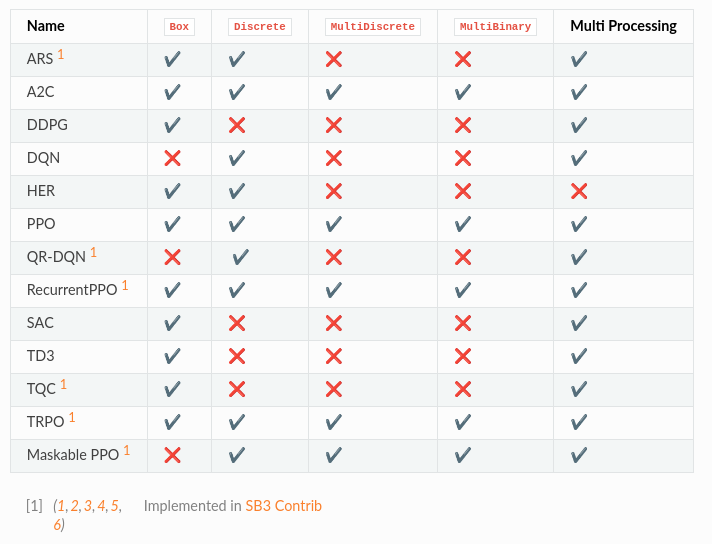
More algorithms (like QR-DQN or TQC) are implemented in our contrib repo.
Examples and main solutions
- Примеры реализаций
- colab-notebooks (github)
Vectorized Environments
Это методы объединения нескольких независимых сред в единую среду. Вместо того, чтобы обучать агента RL в 1 среде за шаг, мы можем обучать его в n средах за шаг. Из-за этого действия, передаваемые в среду, теперь являются вектором (размерности n). То же самое для наблюдений, наград и сигналов об окончании эпизода. В случае пространств наблюдений, не являющихся массивами, таких как Dict или Tuple, где разные подпространства могут иметь разную форму, последующие наблюдения будут являтсья векторами (размерности n).
- Vectorized Environments Wrappers
VёVecEnv- Абстрактная асинхронная векторизованная среда.DummyVecEnv- Создает простую векторизованную оболочку для нескольких сред, последовательно вызывая каждую среду в текущем процессе Python. Это полезно для вычислительно простой среды, такой как cartpole-v1, поскольку накладные расходы на многопроцессорность или многопоточность перевешивают время вычисления среды. Это также можно использовать для методов RL, для которых требуется векторизованная среда, но вы хотите использовать одну среду для обучения.SubprocVecEnv- Создает многопроцессорную векторизованную оболочку для нескольких сред, распределяя каждую среду по отдельному процессу, что позволяет значительно ускорить работу, когда среда является сложной в вычислительном отношении. По соображениям производительности, если ваша среда не привязана к вводу-выводу, количество сред не должно превышать количество логических ядер вашего ЦП.
- Wrappers
VecFrameStack- Оболочка стека кадров для векторизованной среды. Предназначена для наблюдения изображений.StackedObservations- Оболочка сстека кадров для данных, не являющихся изображениями.VecNormalize- Скользящее среднее, нормализующая оболочка для векторизованной среды. поддерживает сохранение/загрузку скользящей среднейVecVideoRecorder- запись обработанного изображения как видео в формате mp4. Для этого на машине должны быть установлены ffmpeg или avconvVecCheckNan- проверка NaN и inf для векторизованной среды. По умолчанию поднимет ворнинг, позволяя узнать, из чего возник NaN/inf.VecTransposeImage¶- Re-order channels, from HxWxC to CxHxW. It is required for PyTorch convolution layersVecMonitor- используется для записи вознаграждения за эпизод, продолжительности, времени и других данных.VecExtractDictObs- извлечение наблюдений в виде словаря
Policy networks
Stable Baselines3 предоставляет сети политик для изображений (CnnPolicies), другие типы входных функций (MlpPolicies) и мультимодальных данных (MultiInputPolicies). Сети SB3 разделены на две основные части.
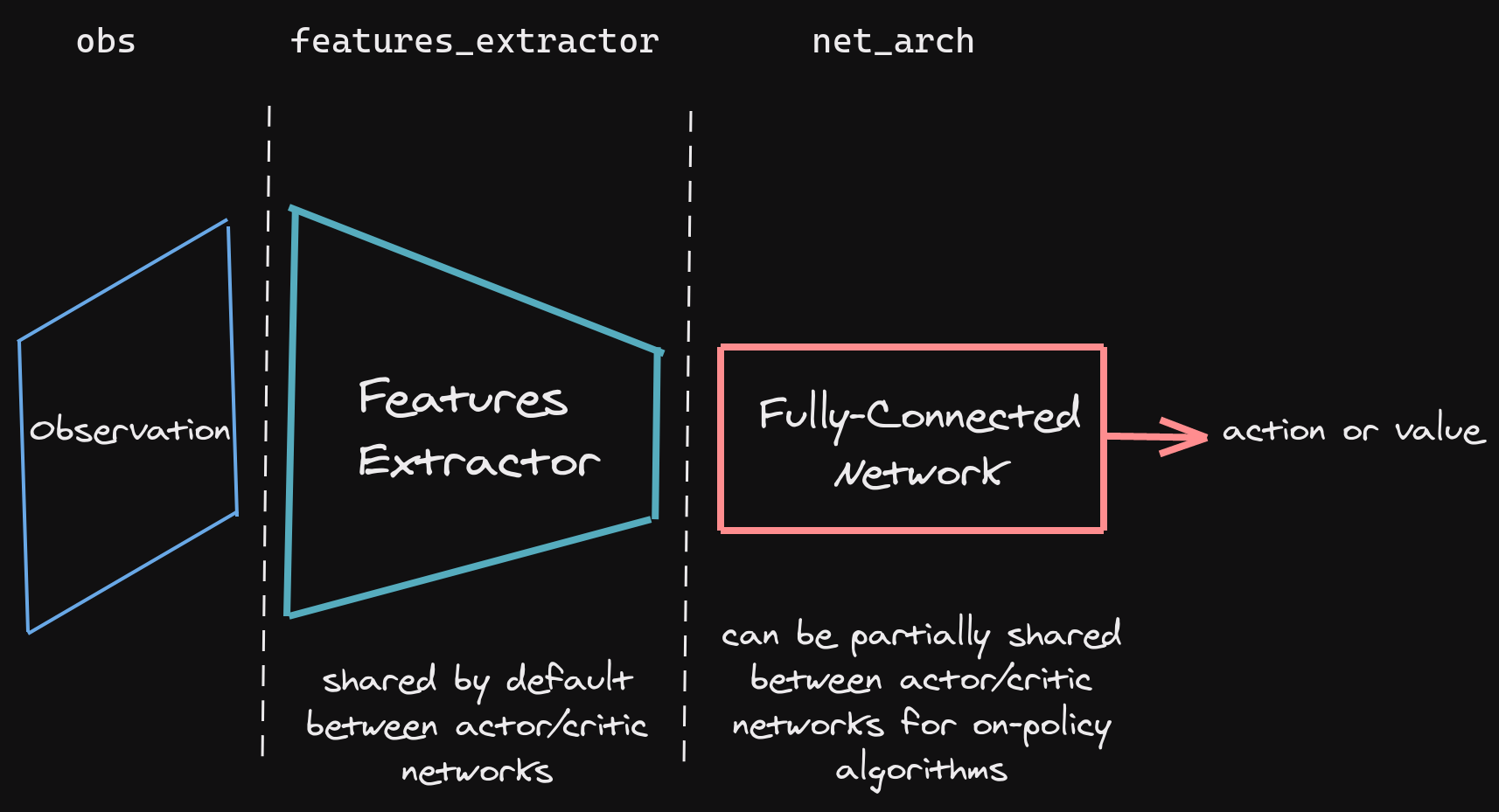
Архитектура сети по умолчанию, используемая SB3, зависит от алгоритма и пространства наблюдения. Вы можете визуализировать архитектуру через model.policy. Один из способов настроить архитектуру сети политик — передать аргументы при создании модели с помощью policy_kwargs.
import gym
import torch as th
from stable_baselines3 import PPO
# Custom actor (pi) and value function (vf) networks
# of two layers of size 32 each with Relu activation function
# Note: an extra linear layer will be added on top of the pi and the vf nets, respectively
policy_kwargs = dict(activation_fn=th.nn.ReLU,
net_arch=dict(pi=[32, 32], vf=[32, 32]))
# Create the agent
model = PPO("MlpPolicy", "CartPole-v1", policy_kwargs=policy_kwargs, verbose=1)
# Retrieve the environment
env = model.get_env()
# Train the agent
model.learn(total_timesteps=20_000)
# Save the agent
model.save("ppo_cartpole")
del model
# the policy_kwargs are automatically loaded
model = PPO.load("ppo_cartpole", env=env)
Если вы хотите иметь настраиваемый экстрактор функций (например, пользовательский CNN при использовании изображений), вы можете определить класс, производный от BaseFeaturesExtractor, а затем передать его модели при обучении.
Stable Baselines3 поддерживает обработку множественных входных данных с помощью пространства Dict Gym. Это можно сделать с помощью MultiInputPolicy, который по умолчанию использует экстрактор функций CombinedExtractor для преобразования нескольких входных данных в один вектор, обрабатываемый net_arch сетью. Подробнее.
Подробнее о реализации сетей для алгоритмов с политиками и вне политик.
Using Custom Environments
Колбеки и интеграции
Дополнительные фичи
- RL Baselines3 Zoo предоставляет сценарии для обучения, оценки агентов, настройки гиперпараметров, отображения результатов и записи видео. Кроме того, включает в себя набор настроенных гиперпараметров для распространенных сред и алгоритмов RL, а также агентов, обученных ПО этим настройкам.
- SB3 Contrib реализует передовые алгоритмы не влезая в ядро баблиотеки.
- Augmented Random Search (ARS)
- Quantile Regression DQN (QR-DQN)
- PPO with invalid action masking (Maskable PPO)
- PPO with recurrent policy (RecurrentPPO aka PPO LSTM)
- Truncated Quantile Critics (TQC)
- Trust Region Policy Optimization (TRPO)
- Imitation Learning
- Behavioral Cloning
- DAgger with synthetic examples
- Adversarial Inverse Reinforcement Learning (AIRL)
- Generative Adversarial Imitation Learning (GAIL)
- Deep RL from Human Preferences (DRLHP)
Смотри еще:
- документация
- пример создания среды (colab)
- Vectorized Environments
- SB3 Contrib стабильно работающие алгоритмы на оснвое sb3. Доки
- rl-baselines3-zoo A Training Framework for Stable Baselines3 Reinforcement Learning Agents
- [gymnasium]
- [reinforcement-learning]
- [pytorch]
- [machine-learning]