MongoDB
Теги: data-bases mongodb
MongoDB basics
MongoDB вышла в 2009 году. Будучи ориентированной на документы базой данных, обычно относящейся к категории NoSQL, она выделяется среди распределенных хранилищ ключей и значений, клонов Amazon Dynamo и повторных реализаций Google BigTable. Ориентируясь на расширенную поддержку операторов и высокопроизводительную онлайн-обработку транзакций (OLTP), MongoDB во многих отношениях ближе к MySQL, чем к пакетно-ориентированным базам данных, таким как HBase.
Ключевые различия между документо-ориентированным подходом MongoDB и традиционной реляционной базой данных заключаются в следующем:
- MongoDB не поддерживает соединения (joins).
- MongoDB не поддерживает транзакции. Однако у него есть некоторая поддержка атомарных операций.
- Схемы MongoDB гибкие. Не все документы в коллекции должны соответствовать одной и той же схеме.
1 и 2 являются прямым результатом огромных трудностей, связанных с масштабированием этих функций в большой распределенной системе при сохранении приемлемой производительности. Хотя в MongoDB отсутствуют соединения, в нем представлены некоторые альтернативные возможности, например. внедрение, которое можно использовать для решения многих из тех же проблем моделирования данных, что и соединения.
Иногда отсутствие транзакций может быть болезненным, но, к счастью, MongoDB поддерживает довольно приличный набор атомарных операций. От простых атомарных операторов увеличения и уменьшения до более функционального «findAndModify», который по существу является атомарным оператором чтения-изменения-записи.
Несмотря на то, что предварительное проектирование схемы, используемое в реляционной модели, весьма продуктивно при планирвоании, обслуживание часто сопряжено с большими затратами. Обработка обновлений схемы в реляционном мире, конечно, выполнима, но имеет свою цену. В MongoDB вы можете динамически добавлять новые свойства в любое время, не беспокоясь об операторах ALTER TABLE, выполнение которых может занять несколько часов, и о сложных сценариях переноса данных. Тем не менее, этот подход имеет свои собственные компромиссы. Например, принудительное применение типов должно тщательно обрабатываться кодом приложения. Пользовательское управление версиями документов может быть желательным, чтобы избежать больших условных блоков для обработки разнородных документов в одной коллекции. Динамический характер MongoDB вполне естественно подходит для работы с динамическим языком, таким как Python. Компромиссы между динамически типизированным языком, таким как Python, и статически типизированным языком, таким как Java, во многих отношениях отражают компромиссы между гибкой, ориентированной на документы моделью MongoDB и предварительным и статически типизированным определением схемы баз данных SQL.
Python позволяет выражать документы и запросы MongoDB естественным образом, используя существующие функции языка, такие как вложенные словари и списки. Если вы работали с JSON в Python, вы сразу же освоитесь с документами и запросами MongoDB. По этим причинам MongoDB и Python представляют собой мощную комбинацию для быстрой итеративной разработки горизонтально масштабируемых серверных приложений.
MongoDB — это документно-ориентированная база данных. Есть два важных отличия от реляционной БД. Во-первых, не все записи должны соответствовать одной и той же схеме. Во-вторых, вы можете вставлять записи друг в друга. Несмотря на эти существенные различия, в MongoDB есть аналоги концепций SQL. Логическая группа записей в базе данных SQL называется таблицей. В MongoDB аналогичным термином является коллекция. Одна запись в базе данных SQL называется строкой. В MongoDB аналогом является документ.

Вместо того, чтобы группировать элементы внутри таблиц, как в SQL, MongoDB группирует их в коллекции. Подобно таблицам SQL, коллекции MongoDB могут иметь индексы для определенных свойств документа для более быстрого поиска, и вы можете читать и записывать их, используя сложные предикаты запросов. В отличие от таблиц SQL, документы в коллекции MongoDB не обязательно должны соответствовать одной и той же схеме.
Connecting to MongoDB with Python
По умолчанию драйвер PyMongo выполняет асинхронную запись. Операции записи включают вставку, обновление, удаление и findAndModify.
Асинхронная запись небезопасна в том смысле, что она не проверяется на наличие ошибок, поэтому выполнение вашей программы может продолжаться без каких-либо гарантий успешного завершения записи. Хотя асинхронная запись повышает производительность, не блокируя выполнение, она может легко привести к неприятным условиям гонки и другим ошибкам целостности данных. По этой причине можно использовать безопасную, синхронную, блокирующую запись. При этом один из распространенных примеров, когда асинхронная запись может иметь смысл, — это когда вы записываете некритические журналы или аналитические данные в MongoDB из своего приложения.
import sys, datetime, pprint, os
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure
from dotenv import load_dotenv
load_dotenv()
ADMINUSERNAME = os.environ.get('ADMINUSERNAME')
ADMINPASSWORD = os.environ.get('ADMINPASSWORD')
def main():
"""
Connect to MongoDB
"""
try:
with MongoClient(
f'mongodb://{ADMINUSERNAME}:{ADMINPASSWORD}@localhost:8082/'
) as client: # uses localhost db
dbh = client["mydb"]
collection = dbh['mycollection'] # get collection
print(collection)
post = { # create document
"author": "Mike",
"text": "My first blog post!",
"tags": ["mongodb", "python", "pymongo"],
"date": datetime.datetime.utcnow()
}
posts = dbh.posts
post_id = posts.insert_one(post).inserted_id # insert
print(f'{post_id=}')
pprint.pprint(posts.find_one({"_id": post_id})) # get inserted
except ConnectionFailure as e:
sys.stderr.write("Could not connect to MongoDB: %s" % e)
sys.exit(1)
if __name__ == "__main__":
main()
Подробнее о простейших операциях с БД
Термин «узел» относится к одному экземпляру процесса демона MongoDB. Обычно на машину приходится один узел MongoDB, но для тестирования или разработки вы можете запустить несколько узлов на одном компьютере. Replica Set — это термин MongoDB для расширенной конфигурации репликации master-slave базы данных. Это похоже на традиционную репликацию master-slave, которую вы найдете в СУБД, таких как MySQL и PostgreSQL, в том смысле, что один узел обрабатывает записи в данный момент времени. В MongoDB выбор ведущего определяется протоколом голосования, и во время аварийного переключения ведомое устройство автоматически повышается до ведущего без вмешательства оператора. Кроме того, драйвер PyMongo поддерживает Replica Set-aware и выполняет автоматическое повторное подключение в случае сбоя к новому мастеру. Таким образом, наборы реплик MongoDB представляют собой конфигурацию репликации «ведущий-ведомый» с отличной обработкой сбоев «из коробки». Для тех, кому приходилось вручную восстанавливаться после сбоя мастера MySQL в производственной среде, эта функция является долгожданным облегчением.
По умолчанию MongoDB вернет успех для вашей операции записи, как только она будет записана на один узел в наборе реплик. Однако для дополнительной безопасности в случае сбоя вы можете захотеть, чтобы ваша запись была зафиксирована в двух или более репликах перед возвратом успеха. Это может помочь гарантировать, что в случае катастрофического сбоя по крайней мере один из узлов в наборе реплик будет иметь вашу запись. PyMongo позволяет легко указать, на скольких узлах вы хотите реплицировать свою запись, прежде чем вернуть успех. Вы просто устанавливаете параметр с именем «w» на количество серверов в каждом вызове метода записи.
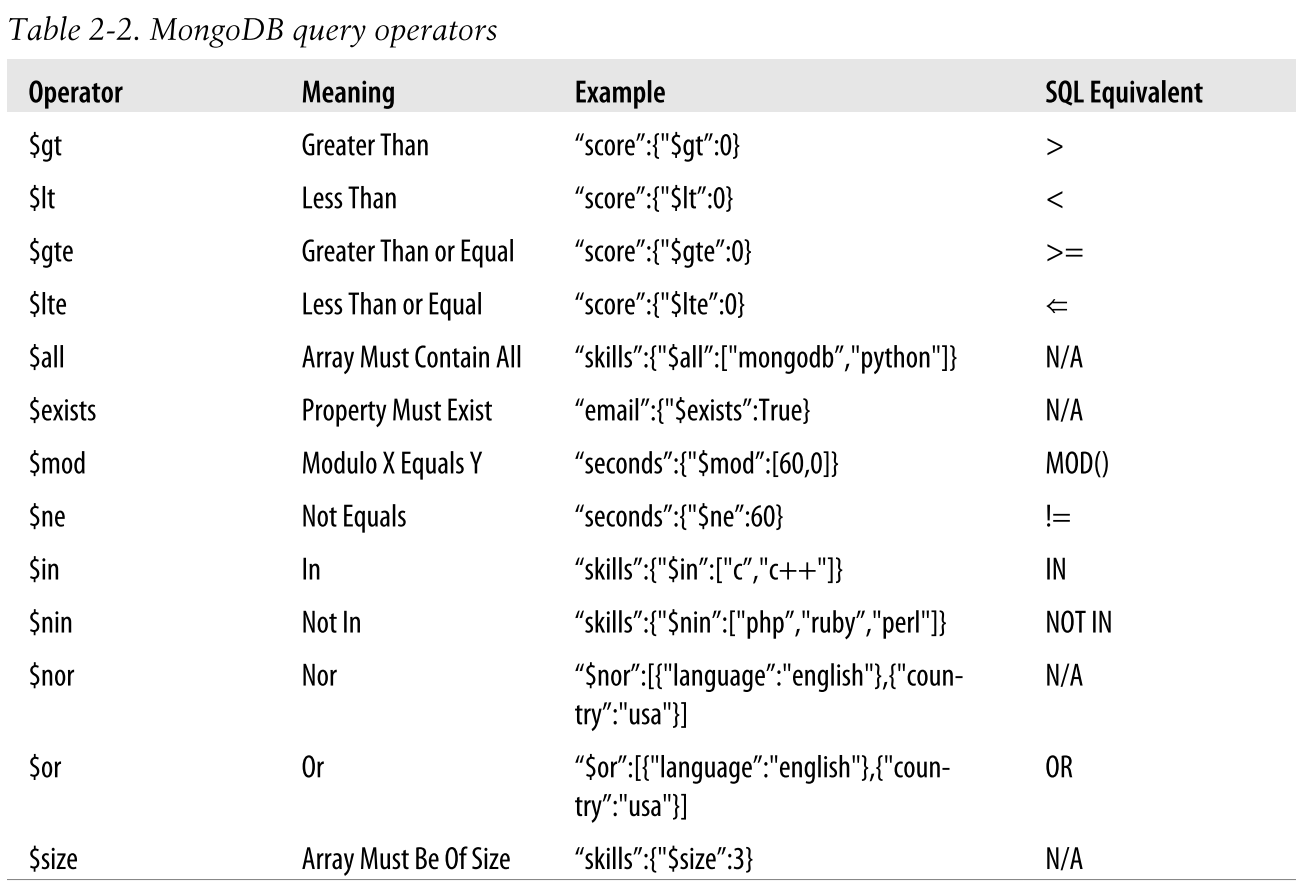
MongoDB Query Language
Запросы MongoDB представлены в виде JSON-подобной структуры, как и документы. Чтобы построить запрос, вы указываете документ со свойствами, которым должны соответствовать результаты. MongoDB рассматривает каждое свойство как имеющее неявное логическое И. Он изначально поддерживает логические запросы ИЛИ, но для этого необходимо использовать специальный оператор ($or). Помимо точных совпадений, в MongoDB есть операторы больше, меньше и т. д.
Запрос одного документа
>>> import pprint
>>> pprint.pprint(posts.find_one())
{'_id': ObjectId('...'),
'author': 'Mike',
'date': datetime.datetime(...),
'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
>>> # or
>>> pprint.pprint(posts.find_one({"author": "Mike"}))
{'_id': ObjectId('...'),
'author': 'Mike',
'date': datetime.datetime(...),
'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
>>> # or
>>> post_id
ObjectId(...)
>>> pprint.pprint(posts.find_one({"_id": post_id}))
{'_id': ObjectId('...'),
'author': 'Mike',
'date': datetime.datetime(...),
'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
post_id - это не строка, необходимо сформировать специальный объект для получения точного ответа на запрос:
from bson.objectid import ObjectId
# The web framework gets post_id from the URL and passes it as a string
def get(post_id):
# Convert from string to ObjectId:
document = client.db.collection.find_one({'_id': ObjectId(post_id)})
bulk inserts
new_posts = [{"author": "Mike",
"text": "Another post!",
"tags": ["bulk", "insert"],
"date": datetime.datetime(2009, 11, 12, 11, 14)},
{"author": "Eliot",
"title": "MongoDB is fun",
"text": "and pretty easy too!",
"date": datetime.datetime(2009, 11, 10, 10, 45)}]
result = posts.insert_many(new_posts)
result.inserted_ids
[ObjectId('...'), ObjectId('...')]
Запрос нескольких документов
for post in posts.find({"author": "Mike"}):
pprint.pprint(post)
{'_id': ObjectId('...'),
'author': 'Mike',
'date': datetime.datetime(...),
'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
{'_id': ObjectId('...'),
'author': 'Mike',
'date': datetime.datetime(...),
'tags': ['bulk', 'insert'],
'text': 'Another post!'}
d = datetime.datetime(2009, 11, 12, 12)
for post in posts.find({"date": {"$lt": d}}).sort("author"):
pprint.pprint(post)
{'_id': ObjectId('...'),
'author': 'Eliot',
'date': datetime.datetime(...),
'text': 'and pretty easy too!',
'title': 'MongoDB is fun'}
{'_id': ObjectId('...'),
'author': 'Mike',
'date': datetime.datetime(...),
'tags': ['bulk', 'insert'],
'text': 'Another post!'}
# or
users = dbh.users.find({"firstname":"jane"}, sort=[("dateofbirth", pymongo.DESCENDING)])
# or add limit for large results
users = dbh.users.find().sort(("score", pymongo.DESCENDING)).limit(10)
users = dbh.users.find().sort(("surname", pymongo.ASCENDING)).limit(20).skip(20)
При просмотре очень больших наборов результатов, когда базовые документы могут быть изменены другими программами одновременно, вы можете захотеть использовать режим моментальных снимков MongoDB. Режим моментальных снимков MongoDB гарантирует, что документы, которые были изменены в течение времени существования запроса, возвращаются в результирующем наборе только один раз. Другими словами, дубликаты устраняются, и вам не нужно о них беспокоиться.
for user in dbh.users.find(snapshot=True):
print(user.get("username"), user.get("score", 0))
Подсчет
posts.count_documents({"author": "Mike"})
2
Создание индексов
result = db.profiles.create_index([('user_id', pymongo.ASCENDING)],
unique=True)
sorted(list(db.profiles.index_information()))
['_id_', 'user_id_1']
user_profiles = [
{'user_id': 211, 'name': 'Luke'},
{'user_id': 212, 'name': 'Ziltoid'}]
result = db.profiles.insert_many(user_profiles)
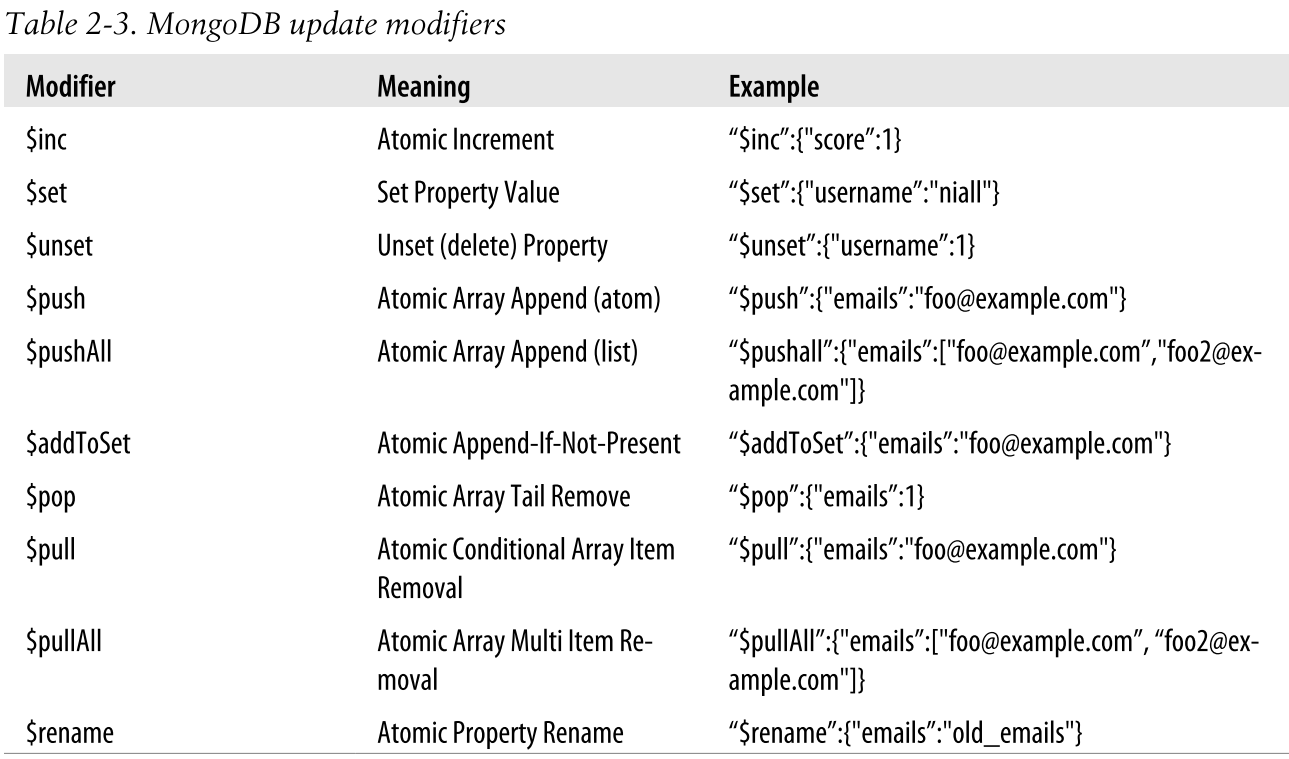
Updating Documents in a Collection
Запросы на обновление в MongoDB состоят из двух частей: спецификации документа, которая информирует базу данных о наборе документов, подлежащих обновлению, и самого документа обновления.
Первая часть, спецификация документа, аналогична документу запроса, который вы используете с find() или find_one().
Вторую часть, документ обновления, можно использовать двумя способами. Самый простой способ — предоставить полный документ, который заменит соответствующий документ в коллекции.
# first query to get a copy of the current document import copy
old_user_doc = dbh.users.find_one({"username":"janedoe"})
new_user_doc = copy.deepcopy(old_user_doc)
# modify the copy to change the email address
new_user_doc["email"] = "janedoe74@example2.com"
# run the update query
# replace the matched document with the contents of new_user_doc
dbh.users.update({"username":"janedoe"}, new_user_doc, safe=True)
Создание всего заменяющего документа может быть обременительным и, что еще хуже, может привести к возникновению условий гонки. Чтобы решить эту проблему, документ обновления поддерживает дополнительный набор операторов MongoDB, называемых «модификаторами обновления». Эти модификаторы обновления включают в себя такие операторы, как атомарное приращение/уменьшение, атомарное включение/выталкивание списка и так далее. Очень полезно знать, какие модификаторы обновления доступны и что они могут делать при разработке приложения.
Мы можем использовать модификатор обновления $set в нашем документе обновления, чтобы избежать запроса перед обновлением. $set изменяет значение отдельного свойства или группы свойств на то, что вы укажете
dbh.users.update({"username":"janedoe"},
{"$set":{"email":"janedoe74@example2.com", "score":1}}, safe=True)
При этом измененеия применяются только к одномуц документу, даже если выбрано несколько. Чтобы применить кор всем - необходима опция multi=True
dbh.users.update({"score":0}, {"$set":{"flagged":True}}, multi=True, safe=True)
Deleting Documents from a Collection
dbh.users.remove({"score":1}, safe=True)
# delete all documents
dbh.users.remove(None, safe=True)
References
Типичные кейсы
Вложенные документы
user_doc = {
"username":"foouser",
"twitter":
{
"username":"footwitter",
"password":"secret",
"email":"twitter@example.com"
},
"facebook":
{
"username":"foofacebook",
"password":"secret",
"email":"facebook@example.com"
},
"irc":
{
"username":"fooirc",
"password":"secret",
}
}
user_doc = dbh.users.find_one({"facebook.username":"foofacebook"})
dbh.users.update(
{"facebook.username":"foofacebook"},
{"$set":{"facebook.username":"bar"}}, safe=True
)
Другой вариант - встраивание нескольких документов под одним ключом, что позволяет более компактно управлять всей структурой.
user_doc = {
"username":"foouser",
"emails":
[
{
"email":"foouser1@example.com",
"primary":True
},
{
"email":"foouser2@example2.com",
"primary":False
},
{
"email":"foouser3@example3.com",
"primary":False
}
]
}
# Insert the user document
dbh.users.insert(user_doc, safe=True)
# Retrieve the just-inserted document via one of its many email addresses
user_doc_result = dbh.users.find_one({"emails.email":"foouser1@example.com"})
# Assert that the original user document and the query result are the same
assert user_doc == user_doc_result
Три наиболее распространенные операции над вложенными документами, встроенными в свойство списка: удаление, вставка и изменение. Каждый из них может быть выполнен атомарно с предоставленными модификаторами обновления.
# Use $pull to atomically remove the "foouser2@example2.com" email sub-document
dbh.users.update(
{"username":"foouser"},
{"$pull":{"emails":{"email":"foouser2@example2.com"}}},
safe=True
)
# Use $pull to atomically remove all email sub-documents with primary not equal to True
dbh.users.update(
{"username":"foouser"},
{"$pull":{"emails":{"primary":{"$ne":True}}}},
safe=True
)
# Use $push to atomically append a new email sub-document to the user document
new_email = {"email":"fooemail4@exmaple4.com", "primary":False}
dbh.users.update(
{"username":"foouser"},
{"$push":{"emails":new_email}},
safe=True
)
# Now make the "foouser2@example2.com" email address primrary
dbh.users.update(
{"emails.email":"foouser2@example2.com"},
{"$set":{"emails.$.primary":True}},
safe=True
)
$ заменяется индексом элемента, соответствующим спецификации документа.
Indexes
Роль индексов в MongoDB очень похожа на их роль в традиционных СУБД, таких как MySQL, PostgreSQL и т. д. MongoDB предлагает два типа готовых индексов: индексы Btree и геопространственные индексы. Индексы btree в MongoDB во многом аналогичны их эквивалентам в MySQL или PostgreSQL.
# If we place an index on property "emails.email"
dbh.users.create_index("emails.email")
# this find_one query can use a btree index
user = dbh.users.find_one({"emails.email":"foouser2@example2.com"})
# Create a compound index on first_name and last_name properties
# with ascending index direction
dbh.users.create_index([(
"first_name", pymongo.ASCENDING),
("last_name", pymongo.ASCENDING)
])
Название индекса можно задать через name. Создание индекса по умолчанию блокирует базу данных. Для больших коллекций создание индекса может занять много времени. Чтобы смягчить влияние этих операций на работающие рабочие базы данных, MongoDB может создавать индексы в фоновом режиме, не блокируя доступ к базе данных. Построение индекса в фоновом режиме может занять немного больше времени и по-прежнему будет вызывать дополнительную нагрузку на систему, но в остальном база данных должна оставаться доступной.
# Create index in the background
# Database remains usable
dbh.users.create_index("username", background=True)
Можно создавать индексы с уникальными значениями и задавать определенные правила добавления. индексы довольно легко удалить из базы данных.
MongoDB является одной из немногих баз данных с готовой поддержкой геопространственного индексирования. MongoDB использует геохэширование, общедоступный алгоритм, разработанный Густаво Нимейером, который преобразует географическую близость в лексическую близость. Следовательно, базу данных, поддерживающую запросы диапазона (например, MongoDB), можно эффективно использовать для запроса точек вблизи и в пределах границ.
More
Один из компромиссов документно-ориентированной базы данных по сравнению с реляционной базой данных заключается в том, что база данных не навязывает вам схему. По этой причине при работе с MongoDB вы должны проявлять бдительность при обработке результатов базы данных. Не полагайте слепо, что результаты всегда будут обладать ожидаемыми свойствами. Прежде чем обращаться к ним, проверьте их наличие. Хотя Python обычно вызывает KeyError и останавливает выполнение, в зависимости от вашего приложения это может привести к потере целостности данных.
Относительно распространенной задачей в приложениях, работающих с базами данных, является обновление существующей записи или, если она не найдена, вставка ее как новой записи. MongoDB удобно поддерживает это как единую операцию, избавляя вас от необходимости реализовывать собственную логику «если-существует-обновить-иначе-вставить». Этот тип операции записи «upsert» в MongoDB реализован в Collection.save(), Collection.update() и Collection.find_and_modify()
# Good implementation using upsert=True
def edit_or_add_session(description, session_id):
dbh.sessions.update(
{"session_id":session_id},
{"$set":{"session_description":description}},
safe=True,
upsert=True
)
Часто необходимо иметь возможность изменять документ атомарно, а также возвращать результат атомарной операции — за один шаг. Это реализовано через Collection.find_and_modify()
# User X adds $20 to his/her account, so we atomically increment
# account_balance and return the resulting document
ret = dbh.users.find_and_modify(
{"username":username},
{"$inc":{"account_balance":20}},
safe=True,
new=True
)
new_account_balance = ret["account_balance"]
Смотри еще:
- [mongo-solutions] Вопросы и решения по mongo
- MongoDB manual
- default mongodb ports
- спецификация метода find() в mongodb
- организация индексов
- Model One-to-One Relationships with Embedded Documents
- движки и контейнеры:
- python mongodb API’s
- docker mongodb
- mongodb minimal docker compose
- pymongo
- pymongo API
- PyMongo create unique index with 2 or more fields (overflow)
- [mongoengine] mongodb orm
- [mongomotor] asyncronous mongo client
- mongomock Small library for mocking pymongo collection objects for testing purpose
- [2022-11-19-daily-note] None в mongoDB, return to dict и Pymongo API TypeError
- NoSQL (Distributed / Big Data) Databases usage in [fastapi]
- odmantic (async orm)
- μMongo: sync/async ODM
- Ming (orm)
- MongoX is an async python ODM (Object Document Mapper) for MongoDB which is built on top of Motor and [pydantic].
- micromongo
- [postgres]
- FaunaDB
- [bd]