Python api for neo4j
Теги: data-bases graphs python
pip install neo4j
Минимальный пример:
from neo4j import GraphDatabase
class HelloWorldExample:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
self.driver.close()
def print_greeting(self, message):
with self.driver.session() as session:
greeting = session.write_transaction(self._create_and_return_greeting, message)
print(greeting)
@staticmethod
def _create_and_return_greeting(tx, message):
result = tx.run("CREATE (a:Greeting) "
"SET a.message = $message "
"RETURN a.message + ', from node ' + id(a)", message=message)
return result.single()[0]
if __name__ == "__main__":
greeter = HelloWorldExample("bolt://localhost:7687", "neo4j", "password")
greeter.print_greeting("hello, world")
greeter.close()
Более реалистичный пример:
from neo4j import GraphDatabase
driver = GraphDatabase.driver("neo4j://localhost:7687", auth=("neo4j", "password"))
def add_friend(tx, name, friend_name):
tx.run("MERGE (a:Person {name: $name}) "
"MERGE (a)-[:KNOWS]->(friend:Person {name: $friend_name})",
name=name, friend_name=friend_name)
def print_friends(tx, name):
for record in tx.run("MATCH (a:Person)-[:KNOWS]->(friend) WHERE a.name = $name "
"RETURN friend.name ORDER BY friend.name", name=name):
print(record["friend.name"])
with driver.session() as session:
session.write_transaction(add_friend, "Arthur", "Guinevere")
session.write_transaction(add_friend, "Arthur", "Lancelot")
session.write_transaction(add_friend, "Arthur", "Merlin")
session.read_transaction(print_friends, "Arthur")
driver.close()
Manual
Hello world пример
import logging
import sys
from neo4j import GraphDatabase
from neo4j.exceptions import ServiceUnavailable
class App:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
# Don't forget to close the driver connection when you are finished with it
self.driver.close()
@staticmethod
def enable_log(level, output_stream):
handler = logging.StreamHandler(output_stream)
handler.setLevel(level)
logging.getLogger("neo4j").addHandler(handler)
logging.getLogger("neo4j").setLevel(level)
def create_friendship(self, person1_name, person2_name, knows_from):
with self.driver.session() as session:
# Write transactions allow the driver to handle retries and transient errors
result = session.write_transaction(
self._create_and_return_friendship, person1_name, person2_name, knows_from)
for row in result:
print("Created friendship between: {p1}, {p2} from {knows_from}"
.format(
p1=row['p1'],
p2=row['p2'],
knows_from=row["knows_from"]))
@staticmethod
def _create_and_return_friendship(tx, person1_name, person2_name, knows_from):
# To learn more about the Cypher syntax, see https://neo4j.com/docs/cypher-manual/current/
# The Reference Card is also a good resource for keywords https://neo4j.com/docs/cypher-refcard/current/
query = (
"CREATE (p1:Person { name: $person1_name }) "
"CREATE (p2:Person { name: $person2_name }) "
"CREATE (p1)-[k:KNOWS { from: $knows_from }]->(p2) "
"RETURN p1, p2, k"
)
result = tx.run(query, person1_name=person1_name,
person2_name=person2_name, knows_from=knows_from)
try:
return [{
"p1": row["p1"]["name"],
"p2": row["p2"]["name"],
"knows_from": row["k"]["from"]
}
for row in result]
# Capture any errors along with the query and data for traceability
except ServiceUnavailable as exception:
logging.error("{query} raised an error: \n {exception}".format(
query=query, exception=exception))
raise
def find_person(self, person_name):
with self.driver.session() as session:
result = session.read_transaction(self._find_and_return_person, person_name)
for row in result:
print("Found person: {row}".format(row=row))
@staticmethod
def _find_and_return_person(tx, person_name):
query = (
"MATCH (p:Person) "
"WHERE p.name = $person_name "
"RETURN p.name AS name"
)
result = tx.run(query, person_name=person_name)
return [row["name"] for row in result]
if __name__ == "__main__":
bolt_url = "%%BOLT_URL_PLACEHOLDER%%"
user = "<Username for database>"
password = "<Password for database>"
App.enable_log(logging.INFO, sys.stdout)
app = App(bolt_url, user, password)
app.create_friendship("Alice", "David", "School")
app.find_person("Alice")
app.close()
Driver и GraphDatabase
Этот объект содержит сведения, необходимые для установления соединения с базой данных Neo4j, включая URI сервера, учетные данные и другую конфигурацию. Объекты neo4j.Driver содержат пул соединений, из которого объекты neo4j.Session могут заимствовать соединения. Закрытие драйвера немедленно отключит все соединения в пуле.
В языках, где безопасность потоков является проблемой, объект драйвера можно считать потокобезопасным.
При создании драйверf обязвтельно необходимо предjcтавить connection URI и аутентификационную информацию. При необходимости могут быть предоставлены дополнительные сведения о конфигурации. Детали конфигурации неизменяемы в течение всего времени существования объекта Driver. Следовательно, если требуется несколько конфигураций (например, при работе с несколькими пользователями базы данных), необходимо использовать несколько объектов-драйверов.
from neo4j import GraphDatabase
class DriverLifecycleExample:
def __init__(self, uri, auth):
self.driver = GraphDatabase.driver(uri, auth=auth)
def close(self):
self.driver.close()
Подробнее о connection URI’s. Там же об аутентификации, про конфиги и логгинг
Допустимые uri:
bolt://host[:port]bolt+ssc://host[:port]bolt+s://host[:port]neo4j://host[:port][?routing_context]neo4j+ssc://host[:port][?routing_context]neo4j+s://host[:port][?routing_context]
[cypher] flow
Работа в канале cypher организована в сессии, транзакции и запросы следующим образом:
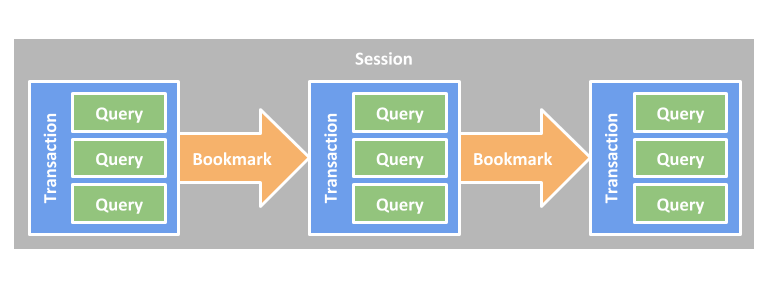
Сессии
Сессии всегда связаны с одним контекстом транзакции, которым обычно является отдельная база данных. Используется механизм закладок, сессии также гарантируют правильную последовательность транзакций, даже если транзакции происходят на нескольких нодах кластера (принцип причинно-следственной связи). Сессии, по сути, обеспечивают контекст для хранения информации о последовательности транзакций в виде закладок.
Когда транзакция начинается, сессия, в котором она содержится, получает соединение из пула соединений драйвера. При фиксации (или откате) транзакции сессия снова разрывает это соединение. Это означает, что только когда сессия выполняет работу, она занимает ресурс соединения. В состоянии простоя такой ресурс не используется.
Из-за последовательности, гарантированной сессией, сессии могут одновременно содержать только одну транзакцию. Для параллельного выполнения следует использовать несколько сесиий. В языках, где важна безопасность потоков, сессии не следует считать потокобезопасными.
Закрытие сессии вызывает откат любой открытой транзакции, а связанное с ней соединение, следовательно, возвращается в пул.
Сессии привязаны к одному транзакционному контексту, указанному при построении. [neo4j] предоставляет каждую базу данных в своем собственном контексте, тем самым запрещая транзакции между базами данных (или сессии) по дизайну. Точно так же сессии, привязанные к разным базам данных, не могут быть связаны причинно-следственной связью путем распространения закладок между ними.
with driver.session(database="example_database", fetch_size=100) as session:
result = session.run("MATCH (a:Person) RETURN a.name AS name")
# do something with the result...
bookmarks. Механизм, обеспечивающий причинно-следственную согласованность между транзакциями в сеансе. Закладки неявно передаются между транзакциями в рамках одного сеанса для удовлетворения требований причинно-следственной согласованности. Могут быть сценарии, в которых вы захотите использовать закладку из одного сеанса в другом новом сеансе. По умолчанию сеансы изначально будут создаваться без закладок
default_Access_Mode. Резервный вариант настройки режима доступа, когда функции транзакций не используются. Как правило, режим доступа устанавливается для каждой транзакции путем вызова соответствующего метода функции транзакции. В других случаях этот параметр наследуется. Обратите внимание, что функции транзакций будут игнорировать/переопределять этот параметр. По умолчанию: Запись
database. База данных, с которой будет взаимодействовать сессия. При работе с базой данных, которая не является базой данных по умолчанию (например, с system базой данных или другой базой данных в Neo4j 4.0 Enterprise Edition), вы можете явно настроить базу данных, для которой драйвер выполняет транзакции. Разрешение псевдонимов базы данных происходит во время создания соединения, которое не находится под контролем сеанса. Поэтому не рекомендуется изменять псевдонимы базы данных во время активных сеансов.
fetch_size. Количество записей, извлекаемых в каждом пакете с сервера. В Neo4j 4.0 появилась возможность извлекать записи пакетами, что позволяет клиентскому приложению контролировать заполнение данных. По умолчанию: 1000 записей
impersonated_user. Пользователи могут запускать транзакции в базе данных как разные пользователи, если им было предоставлено явное разрешение на это. При персонификации пользователя запрос выполняется в полном контексте безопасности данного пользователя, а не аутентифицированного пользователя (т. е. домашней базы данных, разрешений и т. д.).
Доступны два объекта; Session и Query. В сессии можн создавать запросы используя строки на языке [cypher] или объекты Query.
with driver.session() as session:
result = session.run("MATCH (n:Person) RETURN n.name AS name")
# do something with the result...
Методы Session:
- close() закрыть сессию
- run(query, parameters=None, **kwargs) создать транзакцию с автоматической фиксацией
- begin_transaction(metadata=None, timeout=None) создать новую транзакицю (дефолтно на запись)
- [read_transaction(transaction_function, *args, kwargs)](https://neo4j.com/docs/api/python-driver/current/api.html#neo4j.Session.read_transaction) новая транзакция на чтение **deprecated с 5.0
- [write_transaction(transaction_function, *args, kwargs)](https://neo4j.com/docs/api/python-driver/current/api.html#neo4j.Session.write_transaction) **deprecated с 5.0
- execute_write() с 5.0
- execute_read() с 5.0
Доступны так-же методы доступа к закладкам межуд транзакциями.
def get_two_tx(tx):
result = tx.run("UNWIND [1,2,3,4] AS x RETURN x")
values = []
for record in result:
if len(values) >= 2:
break
values.append(record.values())
# or shorter: values = [record.values()
# for record in result.fetch(2)]
# discard the remaining records if there are any
summary = result.consume()
# use the summary for logging etc.
return values
with driver.session() as session:
values = session.read_transaction(get_two_tx)
def create_node_tx(tx, name):
query = "CREATE (n:NodeExample { name: $name }) RETURN id(n) AS node_id"
result = tx.run(query, name=name)
record = result.single()
return record["node_id"]
with driver.session() as session:
node_id = session.write_transaction(create_node_tx, "example")
Транзакции
Транзакции могут включать операции чтения или записи и, как правило, направляются на соответствующий сервер для выполнения, где они будут выполняться полностью. В случае сбоя транзакции необходимо повторить транзакцию с самого начала.
Драйверы Neo4j обеспечивают управление транзакциями через механизм функции транзакций. Этот механизм раскрывается через методы объекта Session, которые принимают функциональный объект, который может воспроизводиться несколько раз на разных серверах до тех пор, пока он не завершится успешно или не истечет время ожидания. Этот подход рекомендуется для большинства клиентских приложений.
Удобная краткая альтернатива — механизм автоматической фиксации транзакции. Это обеспечивает ограниченную форму управления транзакциями для транзакций с одним запросом в качестве компромисса за несколько меньшие накладные расходы кода. Эта форма транзакции полезна для быстрых сценариев и сред, где не требуются гарантии высокой доступности. Это также необходимая форма транзакции для выполнения PERIODIC COMMIT запросов, которые являются единственным типом Cypher Query для управления своими собственными транзакциями.
API неуправляемых транзакций более низкого уровня также доступен для расширенных вариантов использования. Это полезно, когда клиент применяет альтернативный уровень управления транзакциями, в котором обработка ошибок и повторные попытки должны управляться особым образом.
Функции транзакций используются для содержания транзакционных единиц работы. Эта форма транзакции требует минимального шаблонного кода и позволяет четко разделить запросы к базе данных и логику приложения.
Функции транзакций также желательны, поскольку они инкапсулируют логику повторных попыток и обеспечивают максимальную гибкость при замене одного экземпляра сервера на кластер.
Функции транзакций могут вызываться как операции чтения или записи. Этот выбор направит транзакцию на соответствующий сервер в кластерной среде. Если вы работаете в среде с одним экземпляром, эта маршрутизация не имеет значения. Это дает вам гибкость, если вы решите позже использовать кластерную среду.
Прежде чем писать функцию транзакции, важно убедиться, что она спроектирована как идемпотентная. Это связано с тем, что функция может выполняться несколько раз, если первоначальные запуски завершаются неудачно.
from neo4j import unit_of_work
@unit_of_work(timeout=5)
def create_person(tx, name):
return tx.run("CREATE (a:Person {name: $name}) RETURN id(a)", name=name).single().value()
def add_person(driver, name):
with driver.session() as session:
return session.write_transaction(create_person, name)
Реализованы три вида транзакций:
- транзакция с автокоммитом
- явная (explicit) транзакция
- управляемая (manageв) транзакция или функция транзакции (transaction function)
Транзакция с автоматической фиксацией — это базовая, но ограниченная форма транзакции. Такая транзакция состоит только из одного запроса Cypher и не повторяется автоматически в случае сбоя. Следовательно, любые сценарии ошибок должны обрабатываться самим клиентским приложением.
Автокоммит транзакция доступна через neo4j.Session.run()
Транзакции с автоматической фиксацией служат следующим целям:
- простые варианты использования, например, при изучении Cypher или написании одноразовых сценариев.
- такие операции, как пакетные операции загрузки данных, когда драйвер не может знать о зафиксированном состоянии и, следовательно, не может безопасно запросить повторную попытку. В этих обстоятельствах оператору придется выполнить повторную попытку или отменить операцию.
Драйвер не повторяет запросы автоматической фиксации в случае сбоя, поскольку он не знает, какое состояние было зафиксировано в момент сбоя.
from neo4j import Query
def add_person(self, name):
with self.driver.session() as session:
session.run("CREATE (a:Person {name: $name})", name=name)
# Alternative implementation, with a one second timeout
def add_person_within_a_second(self, name):
with self.driver.session() as session:
session.run(Query("CREATE (a:Person {name: $name})", timeout=1.0), name=name)
Явные (explicit) транзакции. Явные транзакции поддерживают несколько операторов и должны создаваться с помощью явного вызова neo4j.Session.begin_transaction(). Это создает новый объект neo4j.Transaction, который можно использовать для запуска [cypher] запроса. Это также дает приложениям возможность напрямую контролировать действия по фиксации и откату.
import neo4j
def create_person(driver, name):
with driver.session(default_access_mode=neo4j.WRITE_ACCESS) as session:
tx = session.begin_transaction()
node_id = create_person_node(tx)
set_person_name(tx, node_id, name)
tx.commit()
def create_person_node(tx):
query = "CREATE (a:Person { name: $name }) RETURN id(a) AS node_id"
name = "default_name"
result = tx.run(query, name=name)
record = result.single()
return record["node_id"]
def set_person_name(tx, node_id, name):
query = "MATCH (a:Person) WHERE id(a) = $id SET a.name = $name"
result = tx.run(query, id=node_id, name=name)
summary = result.consume()
# use the summary for logging etc.
Методы объекта Transaction:
run(query, parameters=None, **kwparameters)commit()rollback()close()closed()
Управляемые транзакции (функции транзакции) — самая мощная форма транзакции, обеспечивающая возможность переопределения режима доступа и повторных попыток.
Они позволяют передать в качестве параметра функциональный объект, представляющий транзакционную единицу работы. Эта функция вызывается один или несколько раз в течение настраиваемого срока, пока не завершится успешно. Результаты должны быть полностью использованы внутри функции, и должны быть возвращены только совокупные значения или значения состояния. Возврат объекта реального результата помешает драйверу правильно управлять соединениями и нарушит гарантии повторных попыток. Функции получают neo4j.ManagedTransaction объект, который реализует только методы run() и декоратор unit_of_work().
def create_person(driver, name)
with driver.session() as session:
node_id = session.execute_write(create_person_tx, name)
def create_person_tx(tx, name):
query = "CREATE (a:Person { name: $name }) RETURN id(a) AS node_id"
result = tx.run(query, name=name)
record = result.single()
return record["node_id"]
Обратите внимание, что функции транзакций должны быть идемпотентными (т. е. результат однократного запуска функции должен быть таким же, как и при ее многократном запуске). Это связано с тем, что драйвер повторно попытается выполнить функцию транзакции, если ошибка будет классифицирована как повторяемая.
Конфигурация транзакции:
transaction_timeout. Можно указать значение тайм-аута, и транзакции, выполнение которых на сервере занимает больше времени, чем это значение, будут прекращены. Это значение переопределит значение, установленное dbms.transaction.timeout. Если значение не указано, значение по умолчанию принимается настройкой сервера. При использовании с Neo4j 4.1 и более ранними версиями драйвер может переопределить любое значение, установленное с помощью dbms.transaction.timeout. В 4.2 и более поздних версиях dbms.transaction.timeout также действует как максимум, который драйвер не может переопределить. Например, при настройке сервера dbms.transaction.timeout=10s драйвер может указать более короткое время ожидания (например, 5 секунд), но не более 10 секунд. Если указано большее значение, транзакция все равно прервется через 10 секунд.
@unit_of_work(timeout=5)
def create_person(tx, name):
return tx.run(
"CREATE (a:Person {name: $name}) RETURN id(a)", name=name
).single().value()
def add_person(driver, name):
with driver.session() as session:
return session.write_transaction(create_person, name)
metadata. Транзакции могут быть помечены метаданными, которые будут прикреплены к выполняемой транзакции и видны в различных выходных данных при перечислении транзакций и запросов, а также в журнале запросов.
@unit_of_work(timeout=5, metadata={"applicationId": "123"})
def create_person(tx, name):
return tx.run(
"CREATE (a:Person {name: $name}) RETURN id(a)", name=name
).single().value()
def add_person(driver, name):
with driver.session() as session:
return session.write_transaction(create_person, name)
Запросы и результаты
Запросы состоят из запроса серверу на выполнение оператора Cypher, за которым следует ответ клиенту с результатом. Результаты передаются в виде потока записей вместе с метаданными и могут постепенно использоваться клиентским приложением.
Для выполнения Cypher Query требуется текст запроса вместе с необязательным набором именованных параметров. Текст может содержать заполнители параметров, которые заменяются соответствующими значениями во время выполнения. Несмотря на то, что можно запускать непараметризованные запросы Cypher, хорошей практикой программирования является использование параметров в запросах Cypher, когда это возможно. Это позволяет кэшировать запросы внутри Cypher Engine, что положительно сказывается на производительности. Значения параметров должны соответствовать значениям Cypher.
Результаты запроса обычно используются в виде потока записей. Драйверы предоставляют способ итерации через этот поток.
def match_person_nodes(tx):
result = tx.run("MATCH (a:Person) RETURN a.name ORDER BY a.name")
return [record["a.name"] for record in result]
with driver.session() as session:
people = session.read_transaction(match_person_nodes)
В рамках сеанса одновременно может быть активен только один поток результатов. Таким образом, если результат одного запроса не используется полностью до выполнения другого запроса, оставшаяся часть первого результата будет автоматически помещена в буфер в объекте результата. Этот буфер обеспечивает промежуточную точку для результатов и разделяет обработку результатов на выборку (перемещение из сети в буфер) и потребление (перемещение из буфера в приложение).
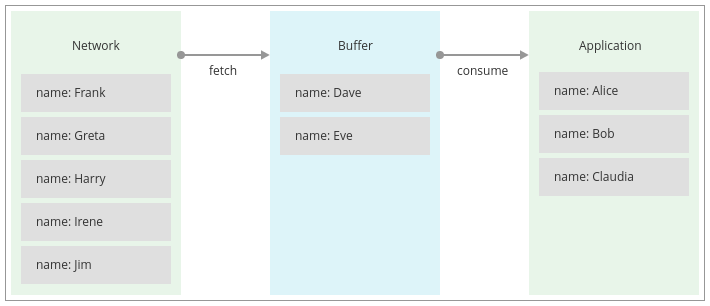
Для больших результатов буфер результатов может потребовать значительного объема памяти. По этой причине рекомендуется потреблять результаты по возможности по порядку.
Клиентские приложения могут управлять более сложными шаблонами запросов, явно сохраняя результаты. Такое явное сохранение может также быть полезным, когда результат необходимо сохранить для будущей обработки. Драйвер дает поддержку этого процесса.
def add_employee_to_company(tx, person, company_name):
tx.run("MATCH (emp:Person {name: $person_name}) "
"MERGE (com:Company {name: $company_name}) "
"MERGE (emp)-[:WORKS_FOR]->(com)",
person_name=person["name"], company_name=company_name)
return 1
def match_person_nodes(tx):
return list(tx.run("MATCH (a:Person) RETURN a.name AS name"))
def add_employees(company_name):
employees = 0
with driver.session() as session:
persons = session.read_transaction(match_person_nodes)
for person in persons:
employees += session.write_transaction(add_employee_to_company, person, company_name)
return employees
Result object
Является результатом запросак БД. Обеспечивает дескриптор результата запроса, предоставляя доступ к записям внутри него, а также к метаданным результата. Также содержит буфер, который автоматически сохраняет неиспользованные записи, когда результаты используются не по порядку. Neo4j.Result присоединяется к активному соединению через neo4j.Session до тех пор, пока все его содержимое не будет буферизовано или использовано.
Доступно:
iter(result)next(result)keys()кортеж с ключамиconsume()потребляет оставшуюся часть результата и возвращает neo4j.ResultSummarysingle(strict: te.Literal[False] = False) → Optional[Record]single(strict: te.Literal[True])→ Record получить следующую и единственную оставшуюся запись или None. Предупреждение генерируется, если доступно более одной записи, но первая из них все еще возвращается.fetch(n)получить n записей из результатаpeek()Получить следующую запись из этого результата, не потребляя его. Это оставляет запись в буфере для дальнейшей обработки.graph()Возвращает экземпляр neo4j.graph.Graph, содержащий все объекты графа - ноды, связи свойства связей. После вызова этого метода результат становится отсоединенным, буферизуя все оставшиеся записи.value(key=0, default=None)Вспомогательная функция, возвращающая остаток результата в виде списка значений.values(*keys)Вспомогательная функция, которая возвращает остаток результата в виде списка списков значений.data(*keys)тоже самое, только в виде списка словарейto_df(expand=False, parse_dates=False)в [pandas] датафреймclosed()
# consume() usage
def create_node_tx(tx, name):
result = tx.run(
"CREATE (n:ExampleNode { name: $name }) RETURN n", name=name
)
record = result.single()
value = record.value()
summary = result.consume()
return value, summary
with driver.session() as session:
node_id, summary = session.execute_write(
create_node_tx, "example"
)
Другие объекты:
Причинная цепочка и закладки
При работе с причинно-следственным кластером транзакции могут быть объединены в цепочку через сеанс для обеспечения причинно-следственной согласованности. Это означает, что для любых двух транзакций гарантируется, что вторая транзакция начнется только после того, как первая будет успешно зафиксирована. Это справедливо даже в том случае, если транзакции выполняются на разных физических элементах кластера.
Внутри причинно-следственная цепочка осуществляется путем передачи закладок между транзакциями. Каждая закладка записывает одну или несколько точек в истории транзакций для конкретной базы данных и может использоваться для информирования членов кластера о необходимости выполнения единиц работы в определенной последовательности. При получении закладки сервер будет блокироваться до тех пор, пока не достигнет соответствующего момента времени транзакции.
Начальная закладка отправляется от клиента к серверу при начале новой транзакции, а окончательная закладка возвращается при успешном завершении. Обратите внимание, что это относится как к транзакциям чтения, так и к транзакциям записи.
Распространение закладок выполняется автоматически в рамках сеансов и не требует каких-либо явных сигналов или настроек от приложения. Чтобы отказаться от этого механизма, для несвязанных единиц работы приложения могут использовать несколько сеансов. Это позволяет избежать накладных расходов на небольшую задержку в причинно-следственной цепочке.
Закладки можно передавать между сеансами, извлекая последнюю закладку из сеанса и передавая ее в построение другого. Несколько закладок также можно комбинировать, если транзакция имеет более одного логического предшественника. Обратите внимание, что только при цепочке между сеансами приложение должно работать с закладками напрямую.
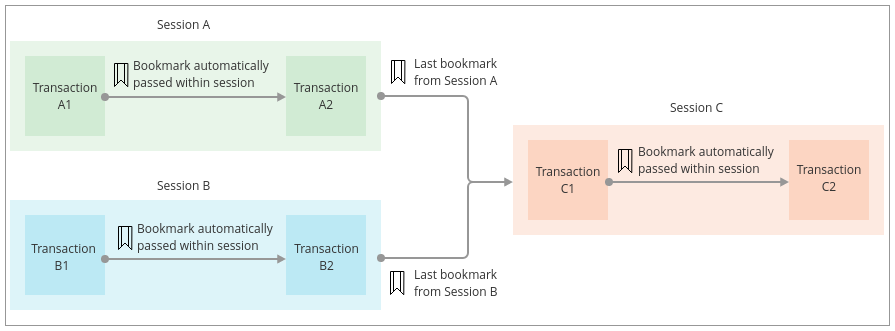
Пример реализации закладки:
from neo4j import GraphDatabase
class BookmarksExample:
def __init__(self, uri, auth):
self.driver = GraphDatabase.driver(uri, auth=auth)
def close(self):
self.driver.close()
# Create a person node.
@classmethod
def create_person(cls, tx, name):
tx.run("CREATE (:Person {name: $name})", name=name)
# Create an employment relationship to a pre-existing company node.
# This relies on the person first having been created.
@classmethod
def employ(cls, tx, person_name, company_name):
tx.run("MATCH (person:Person {name: $person_name}) "
"MATCH (company:Company {name: $company_name}) "
"CREATE (person)-[:WORKS_FOR]->(company)",
person_name=person_name, company_name=company_name)
# Create a friendship between two people.
@classmethod
def create_friendship(cls, tx, name_a, name_b):
tx.run("MATCH (a:Person {name: $name_a}) "
"MATCH (b:Person {name: $name_b}) "
"MERGE (a)-[:KNOWS]->(b)",
name_a=name_a, name_b=name_b)
# Match and display all friendships.
@classmethod
def print_friendships(cls, tx):
result = tx.run("MATCH (a)-[:KNOWS]->(b) RETURN a.name, b.name")
for record in result:
print("{} knows {}".format(record["a.name"], record["b.name"]))
def main(self):
saved_bookmarks = [] # To collect the session bookmarks
# Create the first person and employment relationship.
with self.driver.session() as session_a:
session_a.write_transaction(self.create_person, "Alice")
session_a.write_transaction(self.employ, "Alice", "Wayne Enterprises")
saved_bookmarks.append(session_a.last_bookmark())
# Create the second person and employment relationship.
with self.driver.session() as session_b:
session_b.write_transaction(self.create_person, "Bob")
session_b.write_transaction(self.employ, "Bob", "LexCorp")
saved_bookmarks.append(session_b.last_bookmark())
# Create a friendship between the two people created above.
with self.driver.session(bookmarks=saved_bookmarks) as session_c:
session_c.write_transaction(self.create_friendship, "Alice", "Bob")
session_c.read_transaction(self.print_friendships)
Маршрутизация транзакций с использованием режимов доступа
Транзакции могут выполняться как в режиме чтения, так и в режиме записи В причинно-следственном кластере каждая транзакция будет направляться на соответствующий сервер в зависимости от режима. При использовании одного экземпляра все транзакции будут передаваться на этот сервер.
Маршрутизация Cypher путем идентификации операций чтения и записи может улучшить использование доступных ресурсов кластера. Поскольку серверов чтения обычно больше, чем серверов записи, выгодно направлять трафик чтения на серверы чтения, а не на сервер записи. Это помогает поддерживать доступность серверов записи для транзакций записи.
Режим доступа обычно определяется методом, используемым для вызова функции транзакции. Сеансовые классы предоставляют метод для вызова операций чтения и другой метод для записи.
В качестве запасного варианта для автоматической фиксации и неуправляемых транзакций на уровне сеанса также может быть предоставлен режим доступа по умолчанию. Это используется только в тех случаях, когда режим доступа не может быть указан иначе. Если в этом сеансе используется функция транзакции, режим доступа по умолчанию будет переопределен.
Драйвер не анализирует Cypher и поэтому не может автоматически определить, предназначена ли транзакция для выполнения операций чтения или записи. В результате транзакция записи, помеченная как чтение, все равно будет отправлена на сервер чтения, но при выполнении произойдет сбой.
def create_person_node(tx, name):
tx.run("CREATE (a:Person {name: $name})", name=name)
def match_person_node(tx, name):
result = tx.run("MATCH (a:Person {name: $name}) RETURN count(a)", name=name)
return result.single()[0]
def add_person(name):
with driver.session() as session:
session.write_transaction(create_person_node, name)
persons = session.read_transaction(match_person_node, name)
return persons
Базы данных и контекст выполнения
Neo4j предлагает возможность работы с несколькими базами данных в рамках одной СУБД.
Для Community Edition это ограничено одной пользовательской базой данных плюс system база данных.
С точки зрения драйвера API сеансы имеют область действия СУБД, и базу данных по умолчанию для сеанса можно выбрать при построении сеанса. База данных по умолчанию используется в качестве цели для запросов, которые явно не указывают базу данных с USE.
В среде с несколькими базами данных сервер помечает одну базу данных как базу данных по умолчанию. Это выбирается всякий раз, когда сеанс создается без указания конкретной базы данных по умолчанию. В среде с одной базой данных эта база данных всегда используется по умолчанию.
Вы передаете имя базы данных драйверу во время создания сеанса. Если вы не укажете имя, будет использоваться база данных по умолчанию. Имя базы данных не должно быть null ни, ни пустой строкой.
from neo4j import READ_ACCESS
with driver.session(database="example") as session:
session.run("CREATE (a:Greeting {message: 'Hello, Example-Database'}) RETURN a").consume()
with driver.session(database="example", default_access_mode=READ_ACCESS) as session:
message = session.run("MATCH (a:Greeting) RETURN a.message as msg").single().get("msg")
print(message)
Сопоставление типов
Для передачи параметров и обработки результатов важно знать основы работы Cypher с типами и понимать, как типы Cypher отображаются в драйвере.

Подробнее о сопоставлении типов читай тут
Исключения и обработка ошибок
Py2neo
Py2neo is a client library and comprehensive toolkit for working with Neo4j from within Python applications and from the command line.
pip install py2neo
from py2neo import Graph
graph = Graph()
tx = graph.begin()
for name in ["Alice", "Bob", "Carol"]:
tx.append("CREATE (person:Person name: $name) RETURN person", name=name)
alice, bob, carol = [result.one for result in tx.commit()]
Neomodel
An Object Graph Mapper (OGM) for the neo4j graph database, built on the awesome neo4j_driver
pip install neomodel
from neomodel import StructuredNode, StringProperty, RelationshipTo, RelationshipFrom, config
config.DATABASE_URL = 'bolt://neo4j:test@localhost:7687'
class Book(StructuredNode):
title = StringProperty(unique_index=True)
author = RelationshipTo('Author', 'AUTHOR')
class Author(StructuredNode):
name = StringProperty(unique_index=True)
books = RelationshipFrom('Book', 'AUTHOR')
harry_potter = Book(title='Harry potter and the..').save()
rowling = Author(name='J. K. Rowling').save()
harry_potter.author.connect(rowling)
Смотир еще:
- neo4j-python-driver Neo4j Bolt driver for Python. docs
- Driver API
- API docs
- Async API Documentation
- The Neo4j Python Driver Manual v4.4
- [pytoneo]
- neomodel An Object Graph Mapper (OGM) for the Neo4j graph database.
- pypher Python Cypher Querybuilder
- Пример проекта
- [graphs]
- [cypher]