Scrapy
Scrapy - это dысокоуровневый fcby[hjyysq фреймворк для web-скрапинга и краулинга на python
Создание проекта: scrapy startproject proj_name
Результат:
proj_name/
scrapy.cfg # deploy configuration file
proj_name/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
Краулер можно создать, наслудуясь от класса Spider в spiders/
from scrapy import Spider
class QuotesSpider(Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
АПИ scrapy активно использует колбеки (смотри [python-glossary]). parse() метод будет вызываться для обработки каждого запроса URL-адресов, даже если мы явно не указали Scrapy делать это. Это происходит потому, что parse() это колбек по умолчанию, который вызывается для запросов без явно назначенного обратного вызова.
name и start_urls это определенные в АПИ дефолтные атрибуты класса. start_urls это аналог вот этого:
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
В АПИ scrapy использщуются генераторы. За счет конструкции yield обеспечивается большинство операций извлечения контента из запросов, а за счет колбеков - вызов, в том числе рекурсивный, необходимых операций.
В библиотеке реализован собственный шел, с помощью которого можно попробовать запросы или извлечение данных из объектов запроса, а так-же можно выполнить дебагинг. Пример ниже:
scrapy shell 'http://quotes.toscrape.com/page/1/'
2022-01-16 01:35:35 [scrapy.utils.log] INFO: Scrapy 2.5.1 started (bot: scrapybot)
2022-01-16 01:35:35 [scrapy.utils.log] INFO: Versions: lxml 4.7.1.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 21.7.0, Python 3.8.10 (default, Jun 2 2021, 10:49:15) - [GCC 10.3.0], pyOpenSSL 21.0.0 (OpenSSL 1.1.1m 14 Dec 2021), cryptography 36.0.1, Platform Linux-5.8.0-7630-generic-x86_64-with-glibc2.32
2022-01-16 01:35:35 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor
2022-01-16 01:35:35 [scrapy.crawler] INFO: Overridden settings:
{'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter',
'LOGSTATS_INTERVAL': 0}
2022-01-16 01:35:35 [scrapy.extensions.telnet] INFO: Telnet Password: a6f662f302955377
2022-01-16 01:35:35 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage']
2022-01-16 01:35:35 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2022-01-16 01:35:35 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2022-01-16 01:35:35 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2022-01-16 01:35:35 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2022-01-16 01:35:35 [scrapy.core.engine] INFO: Spider opened
2022-01-16 01:35:36 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None)
2022-01-16 01:35:36 [asyncio] DEBUG: Using selector: EpollSelector
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x7ff2693c20a0>
[s] item {}
[s] request <GET http://quotes.toscrape.com/page/1/>
[s] response <200 http://quotes.toscrape.com/page/1/>
[s] settings <scrapy.settings.Settings object at 0x7ff2693c0d90>
[s] spider <DefaultSpider 'default' at 0x7ff269178dc0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
2022-01-16 01:35:36 [asyncio] DEBUG: Using selector: EpollSelector
In [1]:
Для разбора html используются [css-selectors] и [xpath]. При этом CSS позволяет реализовать навигацию по html, а XPath более функциональный разбор ( а именно извлечение контента). Фактически CSS транслируется в XPath.
Пример извлечения данных с помощью селекторов:
from scrapy import Spider
class QuotesSpider(Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
Результат:
2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from
<200 http://quotes.toscrape.com/page/1/>
{'tags': ['life', 'love'], 'author': 'André Gide',
'text': '“It is better to be hated for what you are than to be loved for what you are not.”'}
2016-09-19 18:57:19 [scrapy.core.scraper] DEBUG: Scraped from
<200 http://quotes.toscrape.com/page/1/>
{'tags': ['edison', 'failure', 'inspirational', 'paraphrased'], 'author': 'Thomas A. Edison',
'text': "“I have not failed. I've just found 10,000 ways that won't work.”"}
Сохранение данных реализовано через Item Pipline. Можно сохранять в .json или в базы данных, сохранять файлы или делать скриншоты. Особых огранисений нет, в основном используется для:
- очистка HTML-данных
- проверка очищенных данных (проверка того, что элементы содержат определенные поля)
- проверка на наличие дубликатов (и удаление их)
- сохранение очищенных элементов в базе данных или в виде файлов
Пример сохранения в MongoDB:
import pymongo
from itemadapter import ItemAdapter
class MongoPipeline:
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert_one(ItemAdapter(item).asdict())
return item
Рекурсивный обход реализуется через колбеки. Пример:
from scrapy import Spider
class AuthorSpider(Spider):
name = 'author'
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
author_page_links = response.css('.author + a')
yield from response.follow_all(author_page_links, self.parse_author)
pagination_links = response.css('li.next a')
yield from response.follow_all(pagination_links, self.parse)
def parse_author(self, response):
def extract_with_css(query):
return response.css(query).get(default='').strip()
yield {
'name': extract_with_css('h3.author-title::text'),
'birthdate': extract_with_css('.author-born-date::text'),
'bio': extract_with_css('.author-description::text'),
}
Этот паук запустится с главной страницы, он будет переходить по всем ссылкам на страницы авторов, вызывая parse_author для каждого из них, а также ссылки пагинации с parse рекурсивно. В данном примере реализован шаблон запроса по селектору extract_with_css а колбеки мы передаем в качестве аргументов в response.follow_all().
Scrapy самостоятельно отфильтровывает повторяющиеся запросы к уже посещенным страницам (это можно настроить отдельно).
Архитектура
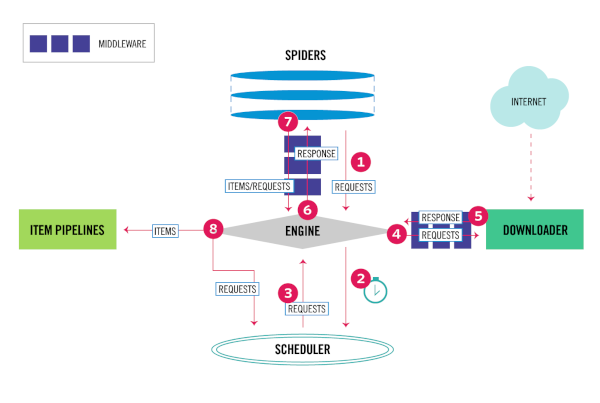
- Engine получает первоначальные запросы на сканирование от Spider
- Engine планирует запросы в Scheduler и запрашивает следующие запросы для сканирования
- Scheduler возвращает следующие запросы движку
- Engine отправляет запросы Downloader, проходя через ПО промежуточного слоя Downloader
- Как только страница завершает загрузку, Downloader генерирует ответ (с этой страницей) и отправляет его в Engine, проходя через промежуточный смлой Downloader
- Engine получает ответ от Downloader и отправляет его Spider для обработки, проходя через промежуточное слой Spider
- Spider обрабатывает ответ и возвращает очищенные элементы и новые запросы в Engine, проходя через промежуточный слой Spider
- Engine отправляет обработанные элементы в Item Pipelines, затем отправляет обработанные запросы планировщику и запрашивает возможные следующие запросы для сканирования.
- Процесс повторяется (с шага 1) до тех пор, пока не закончатся запросы от Scheduler
Engine отвечает за управление потоком данных между всеми компонентами системы и инициирование событий при выполнении определенных действий
Scheduler получает запросы от движка и ставит их в очередь для передачи позже (также в движок), когда движок их запрашивает
Downloader отвечает за получение веб-страниц и передачу их движку, который, в свою очередь, передает их в Spiders
Spiders — это настраиваемые классы, написанные пользователями Scrapy для анализа ответов и извлечения из них элементов или дополнительных запросов
Item Pipelines отвечает за обработку элементов после их извлечения (или очистки) пауками. Типичные задачи включают очистку, проверку и сохранение (например, сохранение элемента в базе данных)
Промежуточный слой Downloader — это специальные перехватчики, которые находятся между движком и загрузчиком и обрабатывают запросы, когда они передаются от движка к загрузчику, и ответы, которые передаются от загрузчика к движку. Их надо использовать для следующих задач:
- обрабатывать запрос непосредственно перед его отправкой загрузчику (т. е. прямо перед тем, как Scrapy отправит запрос на веб-сайт)
- изменить полученный ответ перед передачей его пауку
- отправить новый запрос вместо передачи полученного ответа пауку
- передать ответ пауку, не загружая веб-страницу
- отбрасывать некоторые запросы
Промежуточный слой Spider — это специальные хуки, которые находятся между движком и пауками и могут обрабатывать ввод (ответы) и вывод паука (элементы и запросы). Их надо использовать для следующих задач:
- постобработка колбеков паука - изменение/добавление/удаление запросов или элементов
- постобработка start_requests
- обрабатывать исключения пауков
- вызывать errback вместо обратного вызова для некоторых запросов на основе содержимого ответа
Network для скрапи написан на Twisted, таким образом он является асинхронным (см. [asyncio])
Ссылки на оригинальный материал: один, два
Компоненты
Command line tool
Конфиг устанавливается в scrapy.cfg в ini стиле
scrapy --info - доступные опции
scrapy -h все доступные команды
- startproject создать новый проект
- genspider создать нового спайдера (опционально из темплейта
scrapy genspider [-t template] <name> <domain>) - settings
- runspider Запустите автономный паук в файле Python, не создавая проект.
- shell Запускает оболочку Scrapy для заданного URL-адреса (если он указан) или пуст, если URL-адрес не указан
- fetch Загружает указанный URL-адрес с помощью загрузчика Scrapy и записывает содержимое в стандартный вывод.
- view Запускает оболочку Scrapy для заданного URL-адреса (если он указан) или пустой, если URL-адрес не указан.
- version
Локальные (только для проекта):
- crawl запустить краулер
- check запустить проверку контрактов
- list список доступных спайдеров для проекта
- edit малополезный доступ к редактору
- parse Извлекает указанный URL-адрес и анализирует его с помощью паука, который его обрабатывает, используя метод, переданный с опцией
--callback, илиparse, если колбек не указан - bench Быстрый бенчмарк-тест
Spiders
Пауки — это классы, которые определяют, как будет исследоваться определенный сайт (или группа сайтов), в том числе как выполнять сканирование (т. е. переход по ссылкам) и как извлекать структурированные данные.
Для пауков цикл парсинга проходит примерно так: все начинается с создания начальных запросов для сканирования первых URL-адресов и указнияе функции обратного вызова, которая будет вызываться с ответом, полученным из этих запросов. Первые запросы для выполнения получаются путем вызова метода start_requests(), который (по умолчанию) генерирует запрос для URL-адресов, указанных в start_urls, и метода разбора в качестве функции обратного вызова.
В функции обратного вызова анализируется ответ (веб-страница) и возвращаются объекты. объекты запросмов или итераторы объектов. Объекты запросов также могут содержать обратные вызовы (возможно, рекурсивные).
При анализе содержимого страниц обычно используя селекторы (но вы также можете использовать [BeautifulSoup], lxml или любой другой механизм, который вы предпочитаете). Наконец, элементы, возвращаемые пауком, обычно сохраняются в базе данных (в каком-либо конвейере элементов) или записываются в файл с использованием Feed export. Несмотря на то, что этот цикл применим (более или менее) к любому типу пауков, существуют разные виды пауков по умолчанию, встроенные в Scrapy для разных целей
Основной класс scrapy.Spider Это самый простой паук, от которого наследуются все остальные пауки (включая пауков, поставляемых в комплекте с Scrapy). Никакого специального функционала он не предоставляет. Он просто предоставляет реализацию start_requests() по умолчанию, которая отправляет запросы из атрибута паука start_urls и вызывает анализ метода паука для каждого из полученных ответов.
Атрибуты, котоыре можно определить для паука:
name- адишник, по которому scrapy находит паукаallowed_domains- списко доменов, ограничивающих область поискаstart_urls- список стартовых урлов краулераcustom_settings- кастомные настройки краулера, переопределяющие настройки проекта. Есть набор готовых настроекcrawlerреализует связку с АПИ scrapisettingsнастройки паука. Смотри раздел настроекloggerобычный python logger, который создается с атрибутом name. Смотри про логирпование в scrapy и [logging]
Методы:
from_crawler(crawler, *args, **kwargs)создает паукаstart_requests()Этот метод должен возвращать итерируемый объект с первым Requests для этого паука. Он вызывается Scrapy, когда паук запускается. Scrapy вызывает его только один раз, поэтому безопасно также реализоватьstart_requests()в качестве генератора черезyieldparse(response)Это колбек по умолчанию, используемый Scrapy для обработки загруженных ответов, когда в их запросах не указан обратный вызов.log(message[, level, component])Обертка, которая отправляет сообщение журнала через регистратор Spider, нужна для обратной совместимости.closed(reason)вызывается для закрытия спайдера
Пример:
import scrapy
class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
]
def parse(self, response):
for h3 in response.xpath('//h3').getall():
yield {"title": h3}
for href in response.xpath('//a/@href').getall():
yield scrapy.Request(response.urljoin(href), self.parse)
Спайдер может получать аргументы командной строки. Это делается через переопределение __init__. Смотри тут
Генерик спайдеры, реализованные в библиотеке:
- CrawlSpider Это наиболее часто используемый паук для сканирования обычных веб-сайтов, поскольку он обеспечивает удобный механизм перехода по ссылкам путем определения набора правил. Класс реализует атрибут
rules. Как определять правила краулинга, так-же пример, смотри тут - XMLFeedSpider Предназначен для разбора XML-каналов путем их итерации по определенному имени узла. Итератор можно выбрать из:
iternodes,xmlиhtml. Рекомендуется использовать итераторiternodesиз соображений производительности, поскольку итераторыxmlиhtmlгенерируют сразу весь DOM для его анализа. - CSVFeedSpider Этот паук очень похож на XMLFeedSpider, за исключением того, что он перебирает строки, а не узлы
- SitemapSpider Позволяет сканировать сайт, обнаруживая URL-адреса с помощью файлов Sitemap. Он поддерживает вложенные сайтмапы и обнаружение URL-адресов сайтмапов из robots.txt.
Selectors
Собственный механизм извлечения структуры html-документа. Построен аокруг parsel это библиотека Python под лицензией BSD для извлечения и удаления данных из HTML и XML с использованием селекторов [xpath] и [css-selectors], в сочетании с регулярными выражениями.
Руководство по использованию см. тут
Items
Основная цель скрейпинга — извлечь структурированные данные из неструктурированных источников, как правило, веб-страниц. Пауки могут возвращать извлеченные данные в виде элементов, объектов Python, которые определяют пары ключ-значение. Scrapy поддерживает несколько типов элементов, реализованных в itemadapter. Поддерживаются следующие типы:
scrapy.item.Itemdictdataclass-based classesattrs-based classespydantic-based classes
Пример:
>>> from dataclasses import dataclass
>>> from itemadapter import ItemAdapter, is_item
>>> @dataclass
... class InventoryItem:
... name: str
... price: float
... stock: int
>>>
>>> obj = InventoryItem(name='foo', price=20.5, stock=10)
>>> is_item(obj)
True
>>> adapter = ItemAdapter(obj)
>>> len(adapter)
3
>>> adapter["name"]
'foo'
>>> adapter.get("price")
20.5
>>>
>>> adapter["name"] = "bar"
>>> adapter.update({"price": 12.7, "stock": 9})
>>> adapter.item
InventoryItem(name='bar', price=12.7, stock=9)
>>> adapter.item is obj
True
>>>
>>> adapter.asdict()
{'name': 'bar', 'price': 12.7, 'stock': 9}
>>>
Item Loaders
Загрузчики айтемов предоставляют удобный механизм для заполнения айтемов извлеченными данными. Несмотря на то, что айтемы могут быть заполнены напрямую, загрузчики элементов предоставляют гораздо более удобный API для их заполнения из процесса очистки за счет автоматизации некоторых общих задач, таких как синтаксический анализ необработанных извлеченных данных перед их назначением. Другими словами, айтемы предоставляют контейнер очищенных данных, а загрузчики элементов предоставляют механизм для заполнения этого контейнера. Загрузчики элементов разработаны, чтобы обеспечить гибкий, эффективный и простой механизм для расширения и переопределения различных правил синтаксического анализа полей, либо с помощью паука, либо с помощью исходного формата (HTML, XML и т. д.).
Чтобы использовать загрузчик элементов, вы должны сначала создать его экземпляр. Вы можете создать его экземпляр с объектом айтема или без него, и в этом случае объект айтема автоматически создается в методе __init__ загрузчика айтемов с использованием класса, указанного в атрибуте ItemLoader.default_item_class. Затем вы начинаете собирать значения в загрузчик, обычно используя селекторы. Вы можете добавить более одного значения в одно и то же поле; загрузчик айтемов знает, как «соединить» эти значения позже, используя соответствующую функцию обработки. Собранные данные хранятся внутри в виде списков, что позволяет добавлять несколько значений в одно и то же поле. Если аргумент айтема передается при создании загрузчика, каждое из значений айтема будет сохранено как есть, если оно уже является итерируемым, или заключено в список.
Пример
from scrapy.loader import ItemLoader
from myproject.items import Product
def parse(self, response):
l = ItemLoader(item=Product(), response=response)
l.add_xpath('name', '//div[@class="product_name"]')
l.add_xpath('name', '//div[@class="product_title"]')
l.add_xpath('price', '//p[@id="price"]')
l.add_css('stock', 'p#stock]')
l.add_value('last_updated', 'today') # you can also use literal values
return l.load_item()
Пример использования:
l = ItemLoader(Product(), some_selector)
l.add_xpath('name', xpath1) # (1)
l.add_xpath('name', xpath2) # (2)
l.add_css('name', css) # (3)
l.add_value('name', 'test') # (4)
return l.load_item() # (5)
- Данные из xpath1 извлекаются и передаются через входной процессор поля имени. Результат процессора ввода собирается и сохраняется в лоадере (но еще не присваивается полю).
- Данные из xpath2 извлекаются и передаются через тот же входной процессор, что и в (1). Результат процессора ввода добавляется к данным, собранным в (1) (если они есть).
- Этот случай аналогичен предыдущим, за исключением того, что данные извлекаются из CSS-селектора css и передаются через тот же процессор ввода, что и в (1) и (2). Результат процессора ввода добавляется к данным, собранным в (1) и (2) (если есть).
- Этот случай также аналогичен предыдущим, за исключением того, что собираемое значение назначается напрямую, а не извлекается из выражения XPath или селектора CSS. Однако значение по-прежнему передается через процессоры ввода. В этом случае, поскольку значение не является итератором, оно преобразуется в итератор значение одного элемента перед передачей его процессору ввода, поскольку процессор ввода всегда получает итерируемые объекты.
- Данные, собранные на этапах (1), (2), (3) и (4), проходят через выходной процессор. Результатом процессора вывода является значение, присвоенное полю имени
Таким образом мы можем собирать необходимые данные в лоадере через процессор ввода, а затем проводить необходимую обработку и заполнять поля айтема уже готовыми значениями через процессор вывода. Процессором может быть любая функция - единственное тербование к ней% она должна получать всего один аргумент, который должен быть итерируемым.
Лоадеры объявляются как классы. а процессоры как методы с _in и _out суффаиксами:
from itemloaders.processors import TakeFirst, MapCompose, Join
from scrapy.loader import ItemLoader
class ProductLoader(ItemLoader):
default_output_processor = TakeFirst()
name_in = MapCompose(str.title)
name_out = Join()
price_in = MapCompose(str.strip)
# ...
Build-in процессоры
Для удобства реализовано несколько build-in процессоров
Compose позволяет объединить несколько функций
>>> from itemloaders.processors import Compose
>>> proc = Compose(lambda v: v[0], str.upper)
>>> proc(['hello', 'world'])
'HELLO'
Identity просто возвращает данные. Видимо нужен для передачи данных из входа на выход как есть.
>>> from itemloaders.processors import Identity
>>> proc = Identity()
>>> proc(['one', 'two', 'three'])
['one', 'two', 'three']
Join(separator=’ ‘) возвращает данные, объединенные сепаратором
>>> from itemloaders.processors import Join
>>> proc = Join()
>>> proc(['one', 'two', 'three'])
'one two three'
>>> proc = Join('<br>')
>>> proc(['one', 'two', 'three'])
'one<br>two<br>three'
MapCompose(*functions, **default_loader_context). Процессор, построенный из композиции заданных функций, аналогичный процессору Compose. Отличие этого процессора заключается в том, как внутренние результаты передаются между функциями
>>> def filter_world(x):
... return None if x == 'world' else x
...
>>> from itemloaders.processors import MapCompose
>>> proc = MapCompose(filter_world, str.upper)
>>> proc(['hello', 'world', 'this', 'is', 'something'])
['HELLO', 'THIS', 'IS', 'SOMETHING']
SelectJmes(json_path). Позоляет эффективно извлекать даныне из json на основе библиотеки jmespath.py
>>> from itemloaders.processors import SelectJmes, Compose, MapCompose
>>> proc = SelectJmes("foo") # for direct use on lists and dictionaries
>>> proc({'foo': 'bar'})
'bar'
>>> proc({'foo': {'bar': 'baz'}})
{'bar': 'baz'}
TakeFirst возвращает первое ненулевое/непустое значение из полученных значений
>>> from itemloaders.processors import TakeFirst
>>> proc = TakeFirst()
>>> proc(['', 'one', 'two', 'three'])
'one'
Кроме того, процессоры могут быть объявлены в полях модели Item, если айтем реализован на оснвое scrapy.Item. Пример смотри тут
Контексты
Item Loader Context — это словарь, который используется всеми процессорами ввода и вывода в загрузчике элементов. Его можно передать при объявлении, создании экземпляра или использовании загрузчика элементов. Они используются для изменения поведения процессоров ввода/вывода.
Объект ItemLoader
classscrapy.loader.ItemLoader(item=None, selector=None, response=None, parent=None, **context)
- item (
scrapy.item.Item) — экземпляр элемента для заполнения с помощью последующих вызововadd_xpath(),add_css()илиadd_value() - selector (
Selector) — селектор для извлечения данных при использовании методаadd_xpath(),add_css(),replace_xpath()илиreplace_css() - response (
Response) — ответ, используемый для создания другого селектора с использованиемdefault_selector_class, если не указан аргумент селектора (в большинстве случаев этот аргумент игнорируется).
Если item не задан, он создается автоматически с использованием класса в default_item_class. Все аргументы передаются в контекст лоадера.
Атрибуты и методы:
itemcontextdefault_item_classиспользуется, если не задан айтемdefault_input_processorиспользуется если в операции не задан входной процессорdefault_output_processordefault_selector_classдефолтный класс, используемый для конструирования селектораselector- объект, из которого извлекаются данныеadd_css(field_name, css, *processors, **kw)add_value(field_name, value, *processors, **kw)add_xpath(field_name, xpath, *processors, **kw)get_collected_values(field_name)возвращет собранные значения для поляget_css(css, *processors, **kw)обработать css процессорамиget_output_value(field_name)Возвращает собранные значения, проанализированные с помощью выходного процессора, для данного поля. Этот метод не заполняет и не изменяет элемент.get_value(value, *processors, **kw)обработать значение процессорамиget_xpath(xpath, *processors, **kw)обработать xpath процессорамиload_item()заполнить все поля айтема имеющимися даннымиnested_css(css, **context)создание вложенных загрузчиковnested_xpath(xpath, **context)replace_css(field_name, css, *processors, **kw)аналогично add, но не добавляет, а заменяетreplace_value(field_name, value, *processors, **kw)replace_xpath(field_name, xpath, *processors, **kw)
# HTML snippet: <p class="product-name">Color TV</p>
loader.add_css('name', 'p.product-name')
# HTML snippet: <p id="price">the price is $1200</p>
loader.add_css('price', 'p#price', re='the price is (.*)')
loader.add_value('name', 'Color TV')
loader.add_value('colours', ['white', 'blue'])
loader.add_value('length', '100')
loader.add_value('name', 'name: foo', TakeFirst(), re='name: (.+)')
loader.add_value(None, {'name': 'foo', 'sex': 'male'})
# HTML snippet: <p class="product-name">Color TV</p>
loader.add_xpath('name', '//p[@class="product-name"]')
# HTML snippet: <p id="price">the price is $1200</p>
loader.add_xpath('price', '//p[@id="price"]', re='the price is (.*)')
Вложенные загрузчики используются для умсеньшения дублирования в строках селекторов.
Повторное использование и расширение
Пример (через наследование и переопредлеление процессора)
from itemloaders.processors import MapCompose
from myproject.ItemLoaders import ProductLoader
def strip_dashes(x):
return x.strip('-')
class SiteSpecificLoader(ProductLoader):
name_in = MapCompose(strip_dashes, ProductLoader.name_in)
Item Pipeline
Конвеер айтемов обрабатывает айтем через несколько компонентов, которые выполняются последовательно. Каждый компонент конвейера эайтемов представляет собой класс Python, реализующий простой метод обработки. Пример приводился выше. Смотри доку и больше примеров тут
Feed Exports
Обеспечивает хранение очищенных данных. Вот форматы сериализации, которые поддерживает scrapy:
- JSON
- JSON lines
- CSV
- XML
- Pickle
- Marshal
Так-же реализован доступ к хранилищам в локальных файловых системах, с доступом по ftp S3, GSC и с передачей объектов через стандартный выход.
Requests and Responses
Как правило, объекты Куйгуыеы генерируются в пауках и проходят через систему, пока не достигнут загрузчика, который выполняет запрос и возвращает объект ответа, который возвращается к пауку, выдавшему запрос. Оба класса Request и Response имеют подклассы, которые добавляют функциональность, не требуемую в базовых классах. Они описаны ниже в подклассах запроса и подклассах ответа.
В частности мы можем определять тело запроса, [http-заголовки], cookies, кодировки и другие параметры запроса, а так-же передавать дополнительтные данные в функцию колбека.
Пример:
def parse_page1(self, response):
return scrapy.Request("http://www.example.com/some_page.html",
callback=self.parse_page2)
def parse_page2(self, response):
# this would log http://www.example.com/some_page.html
self.logger.info("Visited %s", response.url)
Кроме того, реализованы:
- обработчики ошибок, котоыре возникают в процессе запроса/ответа
- параметры запроса, например таймаут запрсоа или прокси
- операции остановки загрузки по запросу
Реализовано несколько сабклассов запроса:
- scrapy.http.FormRequest
- scrapy.http.JsonRequest
Объект Response представляет собой HTTP-ответ, который обычно загружается загрузчиком и передается паукам для обработки. Реализует весь набор [http]. Кроме того, реализованы сабклассы:
- TextResponse для доп.кодирования и получения не только бинарных данных
- HtmlResponse
- XmlResponse
Link Extractors
Реализует извлечение ссылок из ответов
Settings
Приоритет настроек:
SETTINGS_PRIORITIES = {
'default': 0,
'command': 10,
'project': 20,
'spider': 30,
'cmdline': 40,
}
Тут объясняется почему нельзя переписать настройки, которые прписаны в самом пауке после создания инстанса паука
Exceptions
В дополнение библиотека поддердживает
- сбор статистики
- отправку сообщений
- извлечение данных из инструментов разработчика браузера
- загрузку и фильтрацию файлов и изображений (в т.ч. отброс повторов. эффективное храниение и т.д.)
пример
import scrapy
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class MyImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
adapter = ItemAdapter(item)
adapter['image_paths'] = image_paths
return item
- АПИ для деплоя на удаленный сервак
- автоматическое управление временем задержки загрузки
- свой собственный шедалер
- поддержку сопрограмм и [asyncio]
- имеет открытый низкоуровневый АПИ
Middlewire
Реализует расширяющие функциональность scrapy хуки двух типаов - даунлоадеры и хуки паков. К примеру обработка [parsing-robots-txt-with-scrapy] осуществляется специальным middlewire, котоырй запускается первым в очереди хуков загрузки.
Порядок исполнения middlewire задается в settings
- For downloader middlewares, the
process_requestmethod is called in increasing order - For downloader middlewares, the
process_responsemethod is called in decreasing order - For spider middlewares, the
process_spider_inputmethod is called in increasing order - For spider middlewares, the
process_spider_outputmethod is called in decreasing order
Пример игнорирования запроса:
from scrapy.exceptions import IgnoreRequest
from scrapy import log
class CustomDownloaderMiddleware(object):
def process_response(self, request, response, spider):
log.msg("In Middleware " + response.url, level=log.WARNING)
if response.url == "http://www.achurchnearyou.com//":
raise IgnoreRequest()
else:
return response
Запуск пауков из скрипта
- CrawlerProcess несколько пауков в одном процессе
- CrawlerRunner запуск паука в готовом “реакторе” - требует дополнительного конфигурирования самого реактора. Все так-же в одном процессе
Смотри еще:
- [crawlers]
- [selenium]
- [splash]
- [playwright]
- [xpath]
- [scrapyd] an application for deploying and running Scrapy spiders. It enables you to deploy (upload) your projects and control their spiders using a JSON API
- spiderkeeper admin ui for scrapy/open source scrapinghub
- crawlab Distributed web crawler admin platform for spiders management regardless of languages and frameworks.
- scrapy-poet Page Object pattern for Scrapy. Allows to write spiders where extraction logic is separated from the crawling one. With scrapy-poet is possible to make a single spider that supports many sites with different layouts
- [2022-02-12-daily-note] парсинг sitemap, фильтрацияи и способы обхода в scrapy
- [parsing-robots-txt-with-scrapy]
- [scrapy-rotating-proxy]
- scrapy playbook Everything you need to know to become a Scrapy Pro!